一、Cache基本原理&概念
1.1 存储系统存在的问题
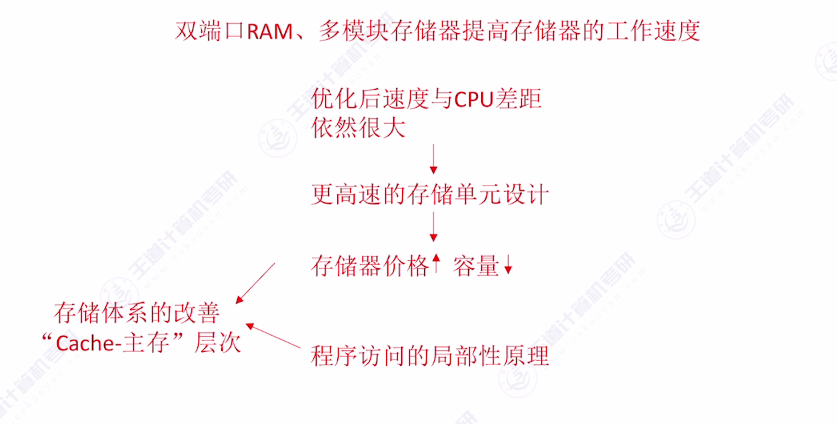

- 主存优化方法: 采用双端口RAM和多模块存储器提高主存工作速度
- 速度差距问题: 即使优化后,主存速度与CPU运算速度差距依然很大
- 高速存储方案: 设计更高速的存储单元(如SRAM替代DRAM),但会导致成本上升或容量下降
1.2 Cache的工作原理
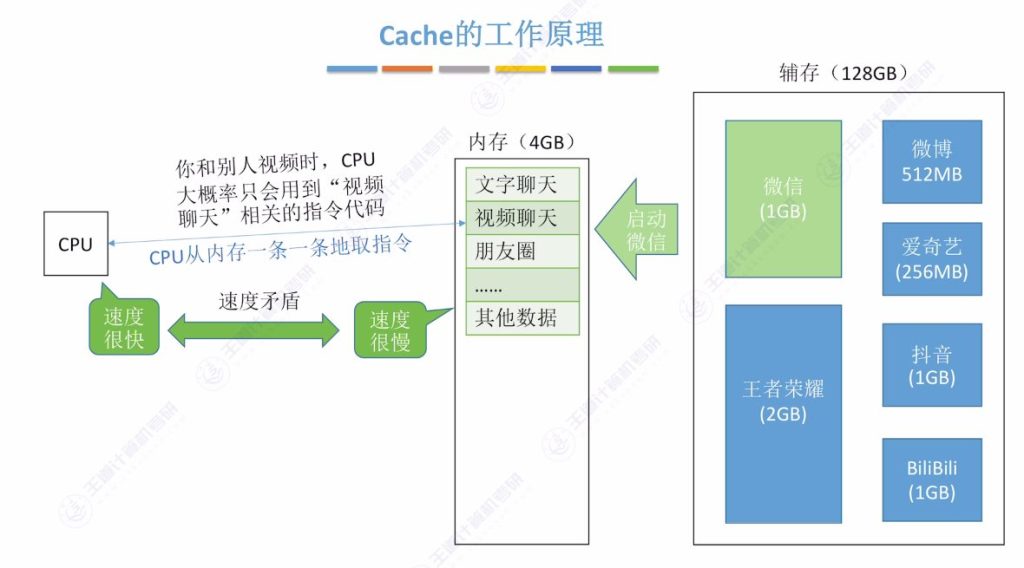
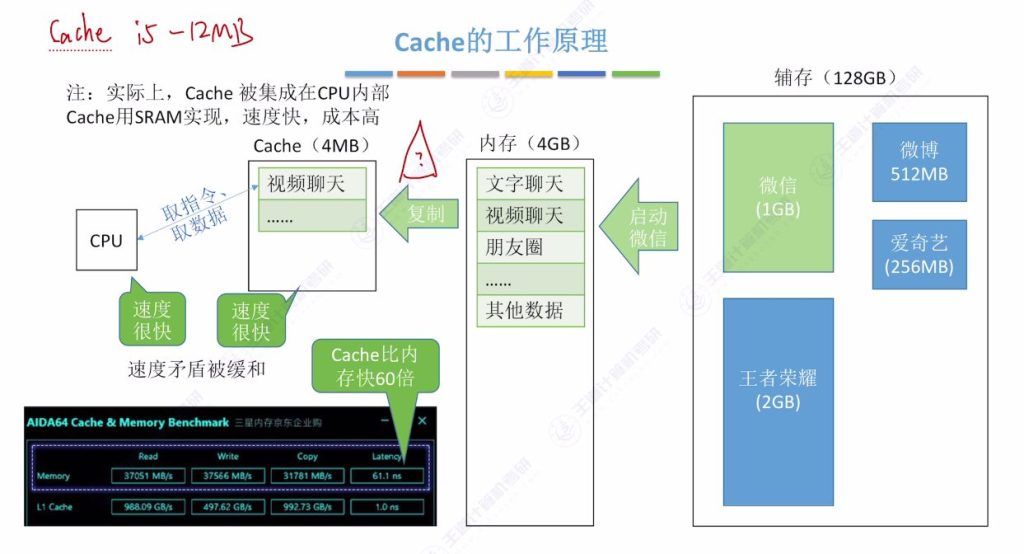
- 基本概念: 在CPU和主存之间增加高速缓冲存储器层(Cache)
- 工作方式: 将频繁访问的数据复制到Cache中,CPU优先从Cache读取数据
- 硬件实现: 现代计算机通常将Cache集成在CPU内部,使用SRAM芯片实现
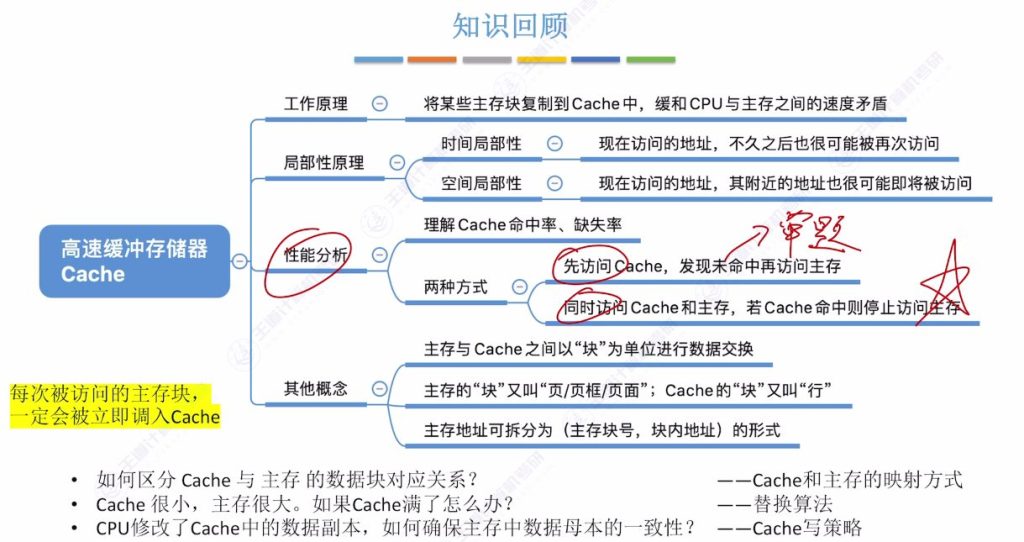
1.3 局部性原理
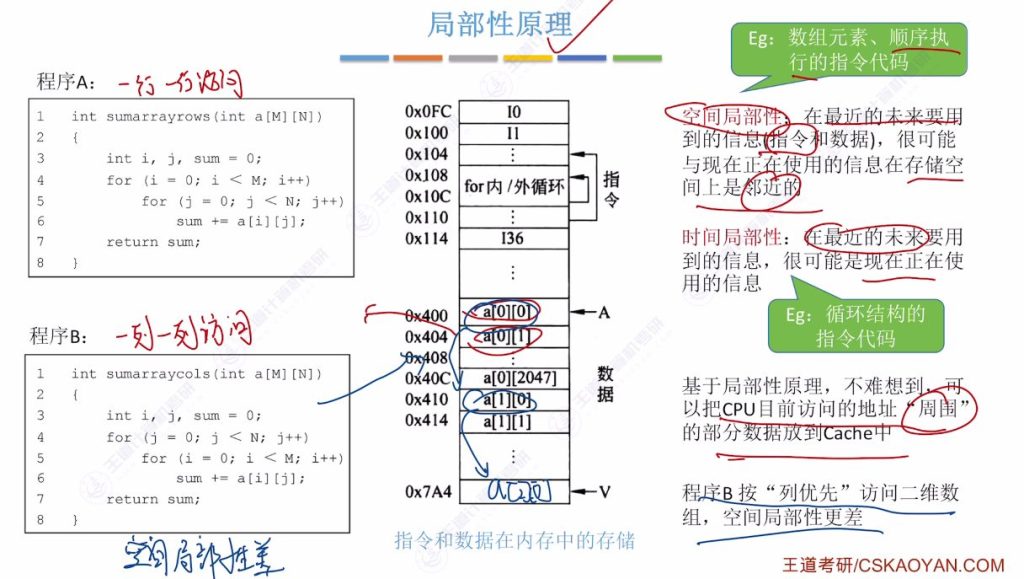
- 空间局部性: 最近未来可能用到的信息很可能在当前使用信息的存储空间周围
- 数据示例: 数组元素按行存储时,访问a00后很可能访问a01、a02等相邻元素
- 指令示例: 程序指令在内存中顺序存放,执行时通常顺序访问
- 时间局部性: 最近未来可能用到的信息很可能是当前正在使用的信息
- 循环结构: 循环体中的指令和数据会被重复访问
- 变量访问: 循环变量(如i、j、sum)因循环结构会被频繁访问
- 访问方式影响:
- 按行访问(程序A)空间局部性好,运行效率高
- 按列访问(程序B)空间局部性差,运行效率低
1.4 性能分析
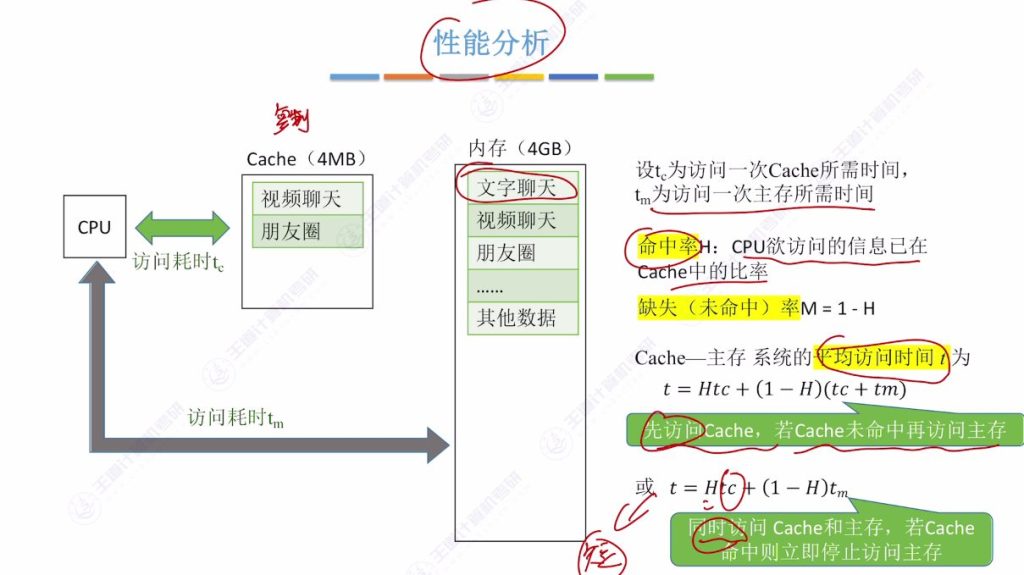

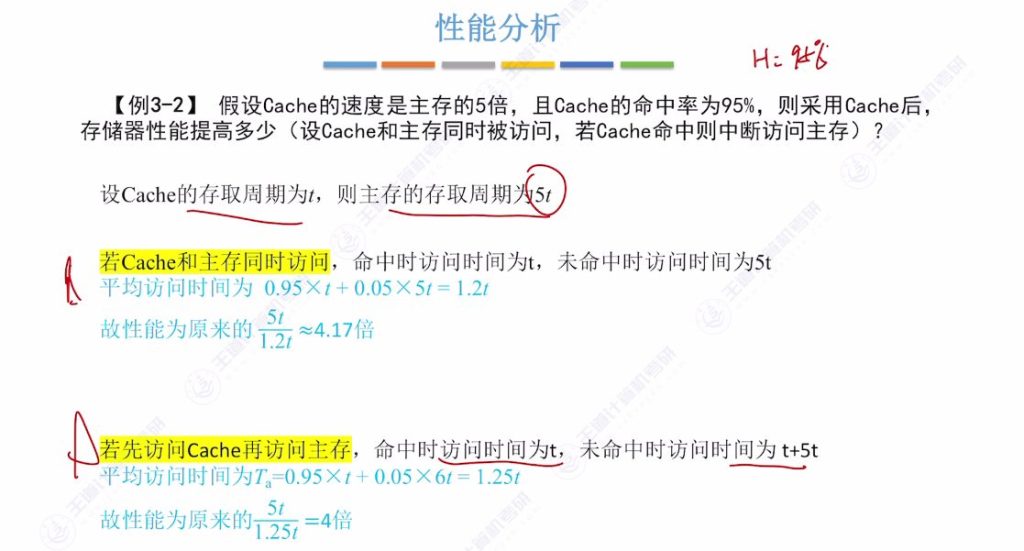
1.5 性能分析案例

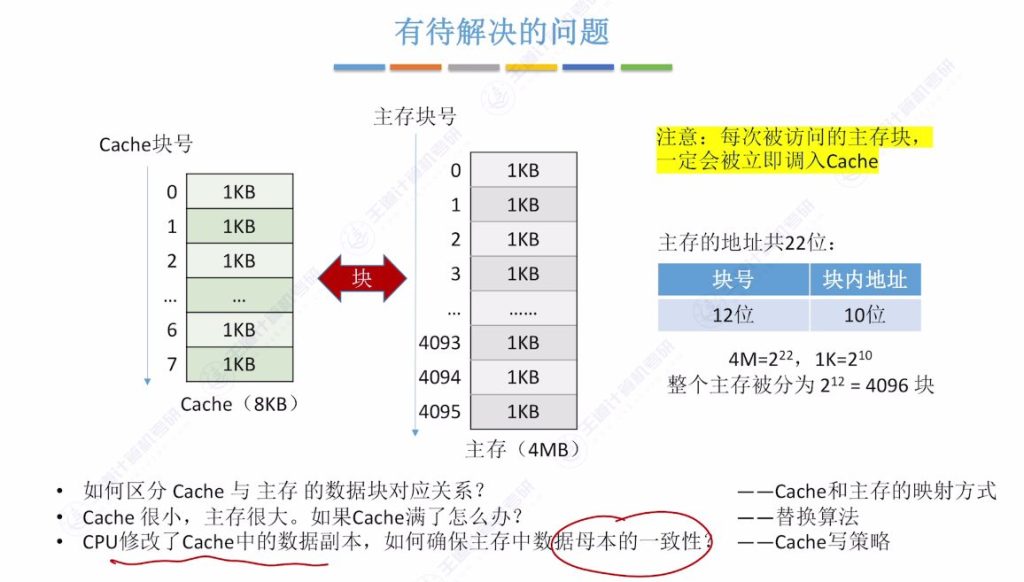
1.6 有待解决的问题
如何界定”周围”的数据?
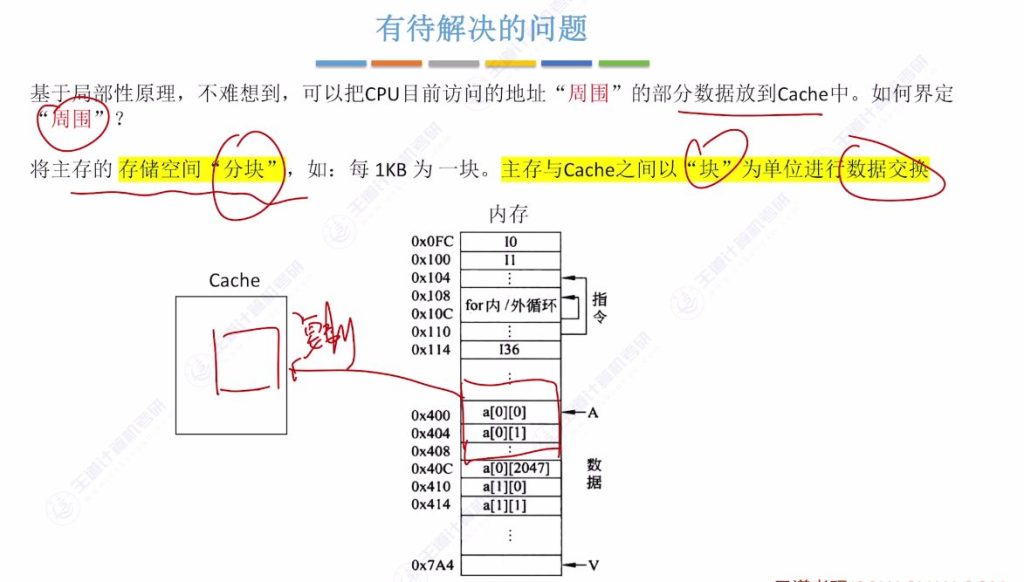
- 分块解决方案: 将主存存储空间划分为大小相等的块(如每1KB为一块),以块为单位界定”周围”数据范围
- 访问机制: 当CPU访问某个地址时,会将该地址所属的整个主存块复制到Cache中
- 示例说明: 访问数组元素a[0][0](地址0x400)时,会将其所属的1KB主存块全部调入Cache
主存与Cache的数据交换单位
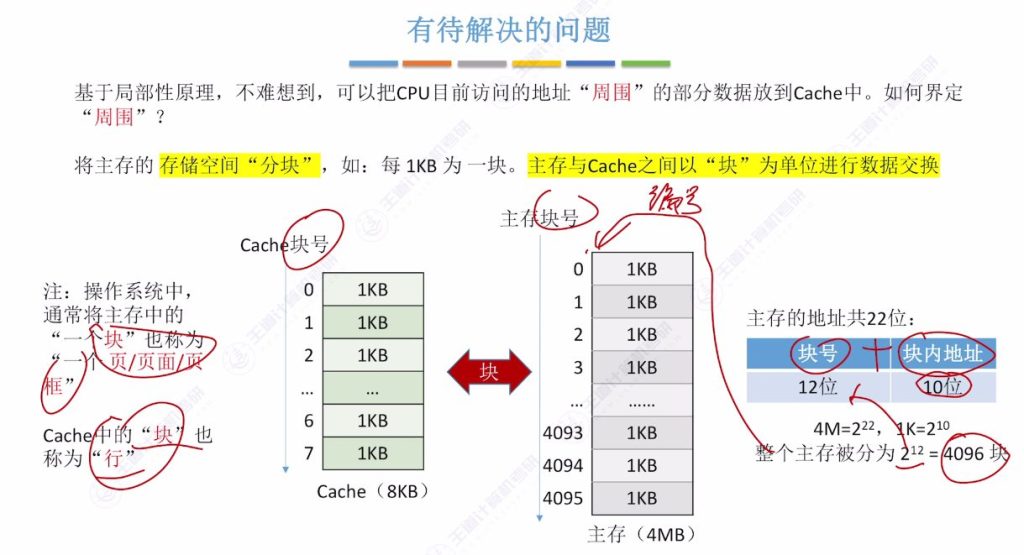
Cache与主存块之间的对应关系问题
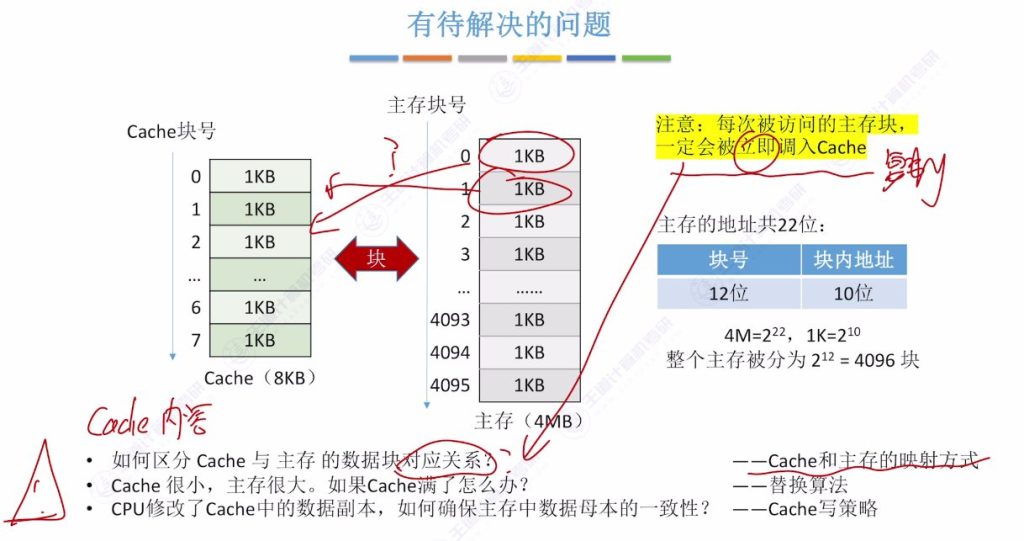
- 核心问题: 如何记录主存块与Cache块之间的映射关系
- 访问流程:
- CPU优先从Cache查找数据
- 未命中时访问主存,并将访问的主存块立即调入Cache
- 数据复制过程不会删除主存原始数据
- 后续解决: 该问题将在”Cache和主存的映射方式”小节详细探讨
Cache满了之后的处理办法
- 容量矛盾: Cache容量远小于主存,只能存储主存数据的一小部分
- 核心问题: 当Cache空间已满时,如何选择替换哪些数据块
- 后续解决: 该问题将在”替换算法”小节详细探讨
如何保证数据副本与数据母本的一致性?
- 数据修改场景: CPU修改Cache中的数据副本时,主存中的数据母本未同步更新
- 一致性问题: 需要确保Cache副本与主存母本的数据一致性
- 后续解决: 该问题将在”Cache写策略”小节详细探讨
1.7 知识回顾
二、Cache和主存映射方式
2.1 知识总览
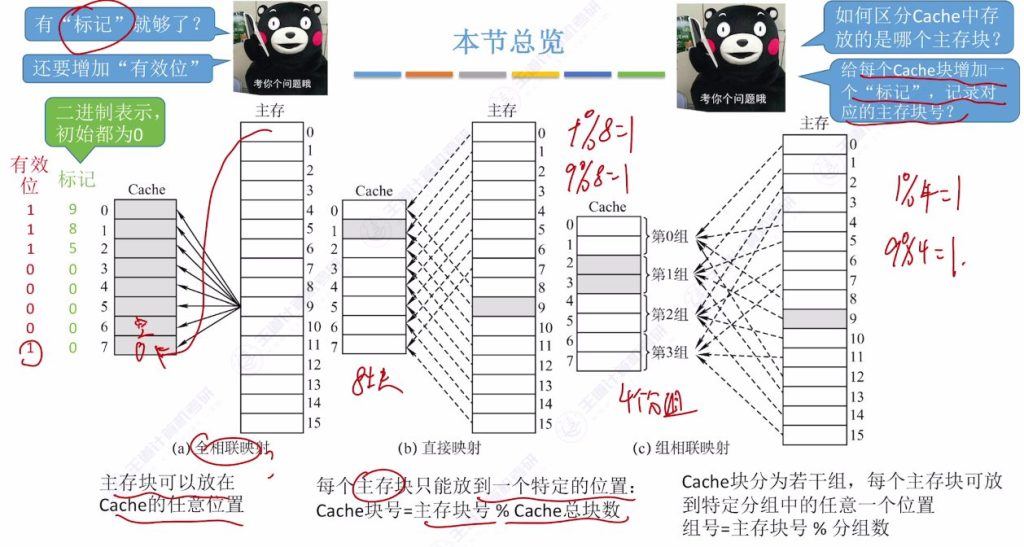
三种映射方式
- 全相联映射:
- 定义:主存块可存入Cache任意位置
- 特点:Cache行数据可能来自主存任意位置
- 直接映射:
- 定位规则:主存块号 mod Cache总块数
- 组相联映射:
- 分组规则:将Cache块分组(如图中8块分4组,每组2块)
- 定位方法:主存块号 mod 组数确定目标组,组内任意存放
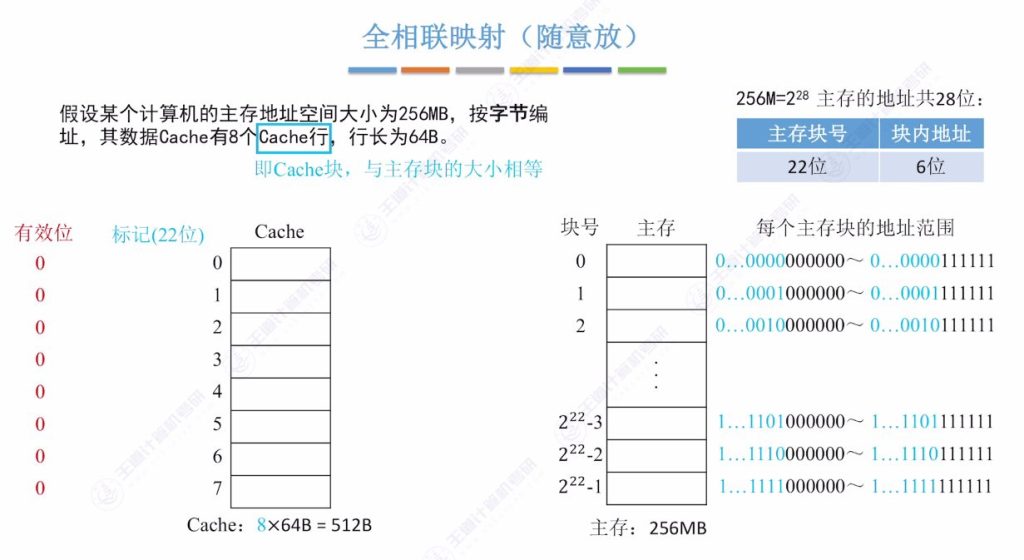
Cache块标记与有效位
- 标记机制:
- 每个Cache块记录对应主存块号作为标记(22位二进制)
- 示例:标记为9/8/5表示Cache块分别存有9/8/5号主存块副本
- 有效位必要性:
- 硬件初始化时标记位全为0,需用1位标识标记有效性(1有效/0无效)
- 示例:仅当有效位为1且标记匹配时,才认定Cache命中
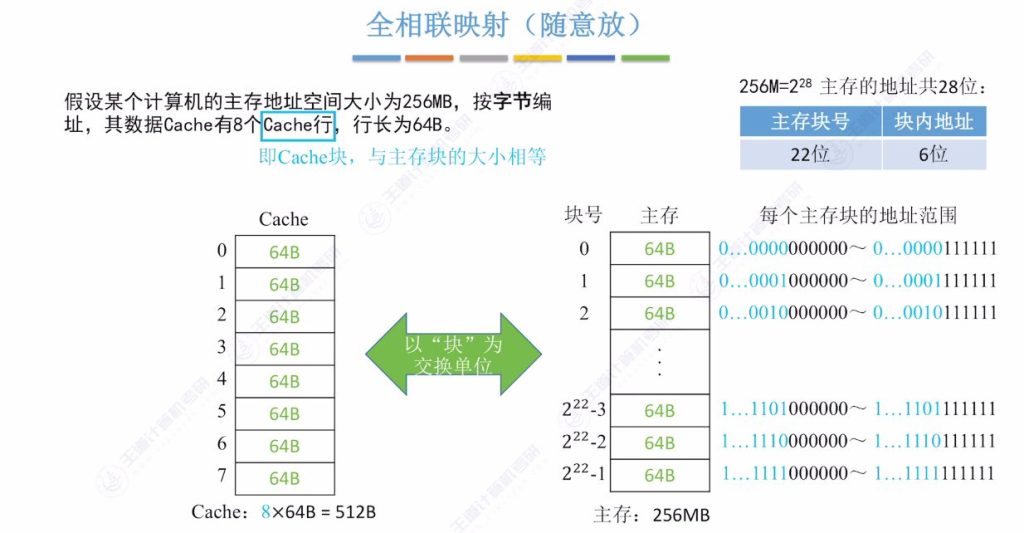
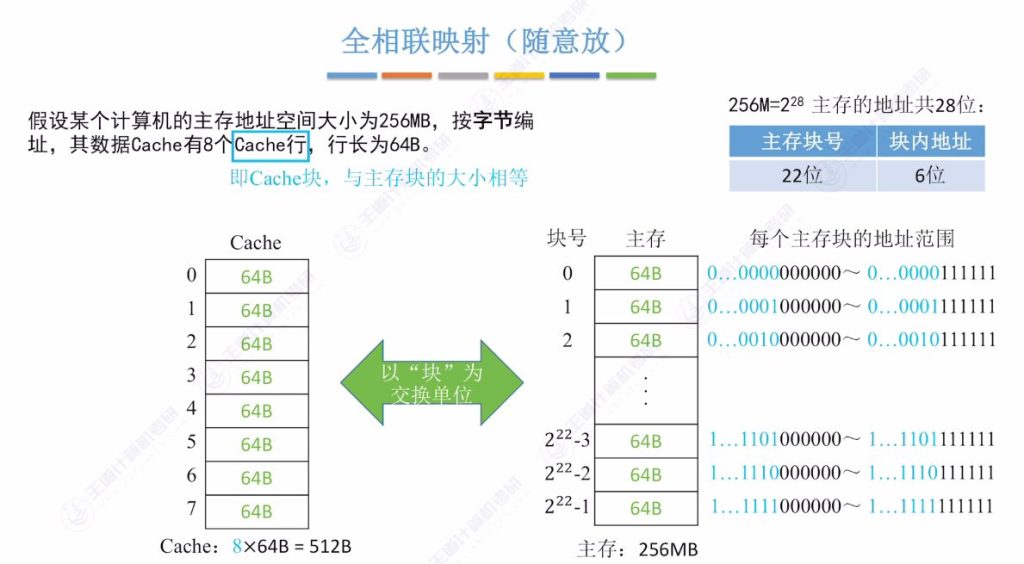
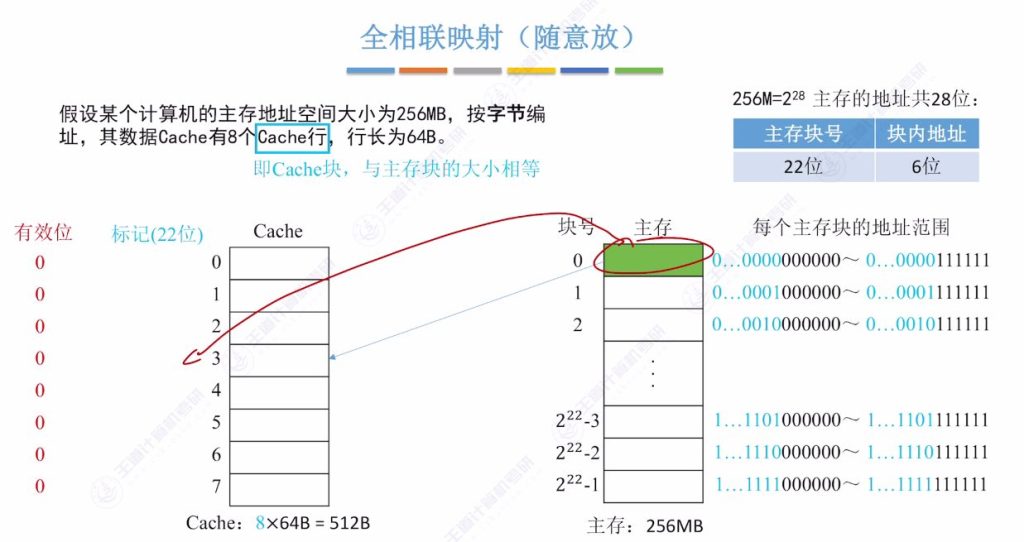
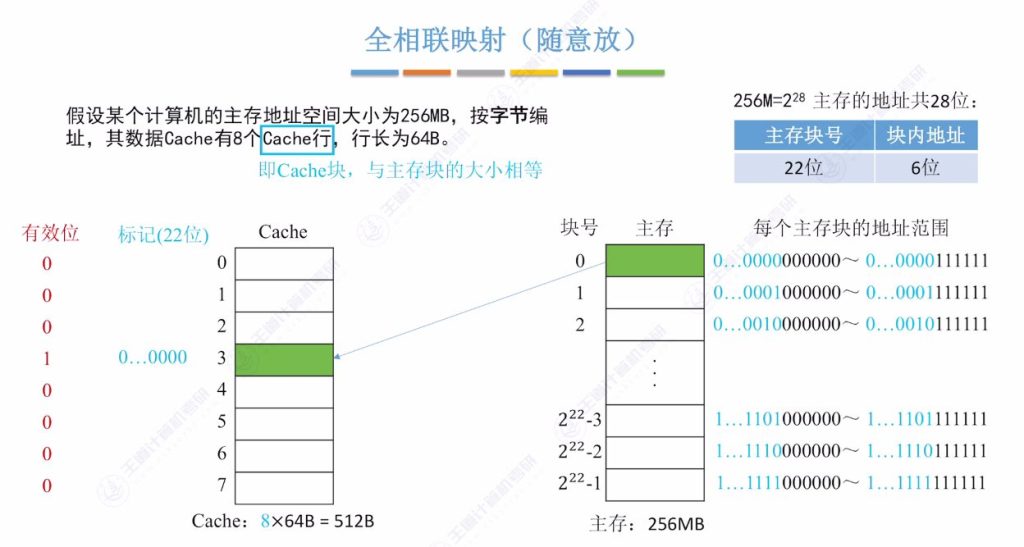
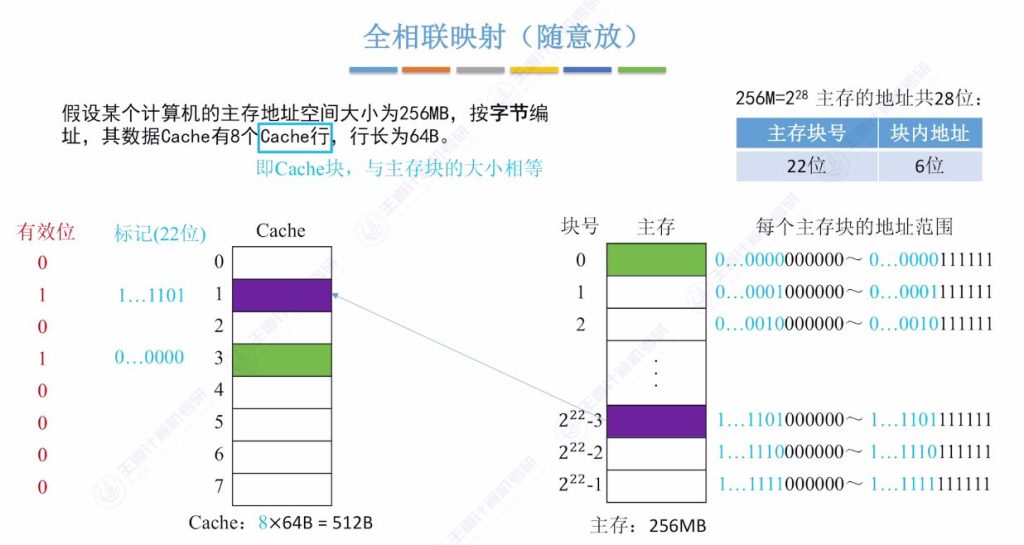
2.2 全相联映射(随意放)
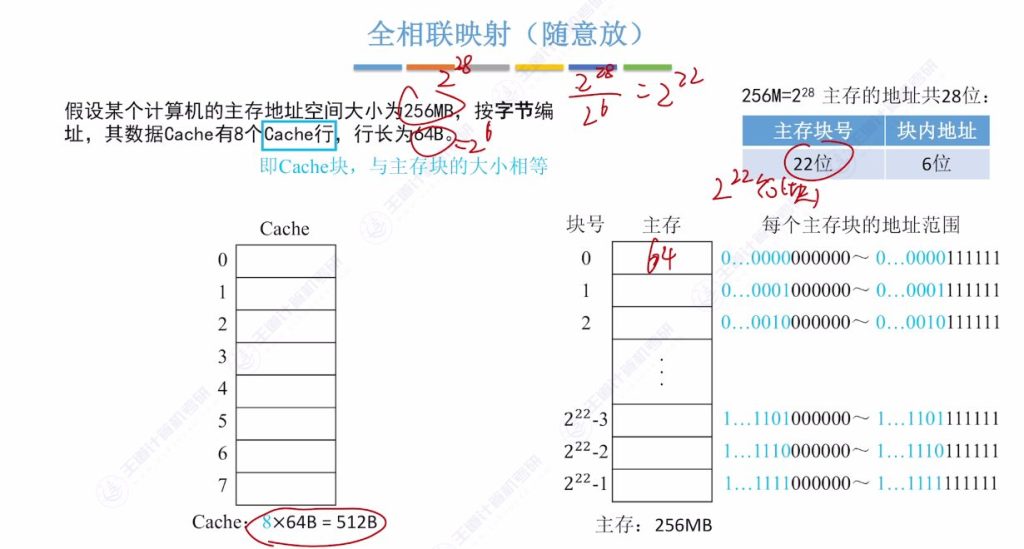
全相联映射的定义
- 系统配置示例:
- 主存:256MB(228字节)按字节编址
- Cache:8行×64字节/行=512B
- 主存分块:222块(22位块号+6位块内地址)
- 映射特点:
- 主存块可放入Cache任意空闲位置
- 标记记录:需22位存储主存块号(如地址0x000000标记为22个0)
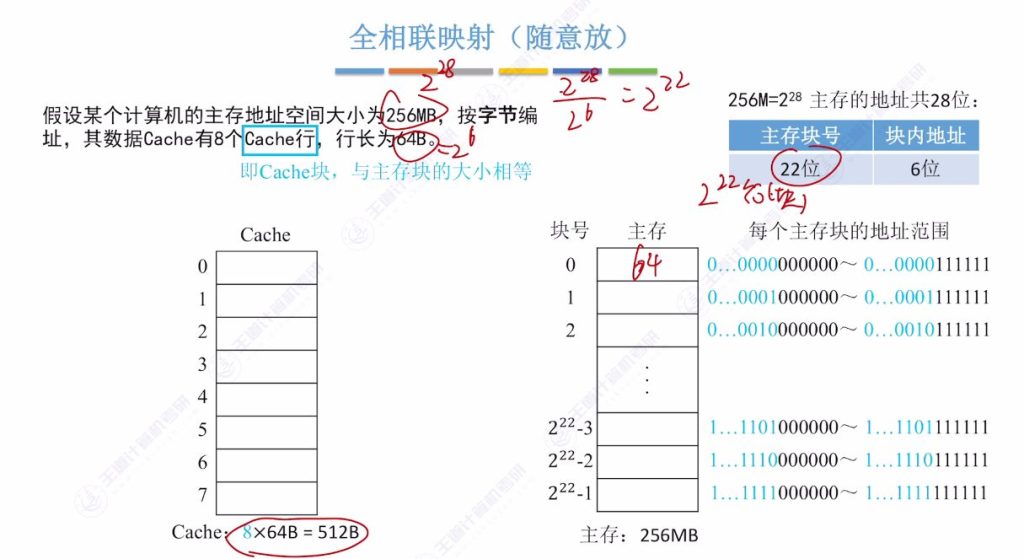
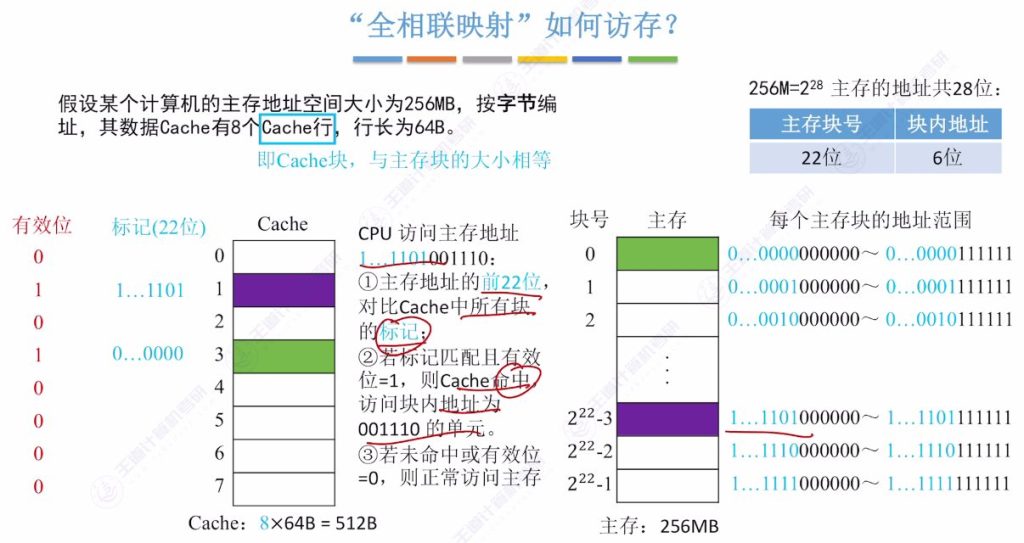
全相联映射的访存过程
- 命中判断流程:
- 提取访存地址前22位(主存块号)
- 并行比较所有Cache行的标记
- 检查有效位为1且标记匹配则命中
- 未命中处理:
- 访问主存获取数据
- 将主存块调入任意空闲Cache行,更新标记和有效位
- 地址解析:
- 命中时用后6位块内地址定位Cache内具体字节
- 示例:地址[22位块号][6位块内地址]中,块号用于标记匹配,块内地址用于数据定位
全相联映射过程

2.3 “全相联映射”如何访存?
2.4 直接映射(只能放固定位置)
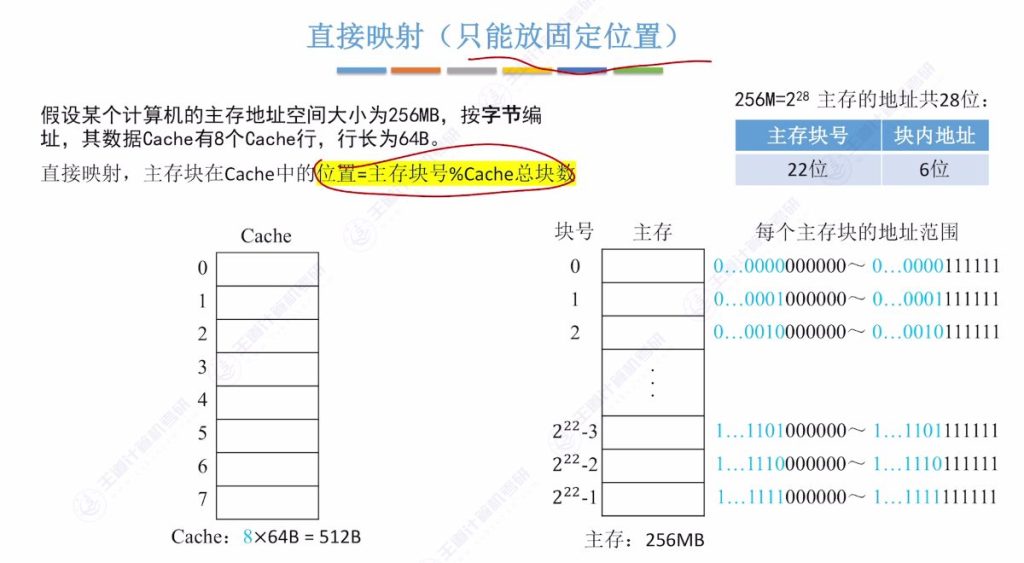
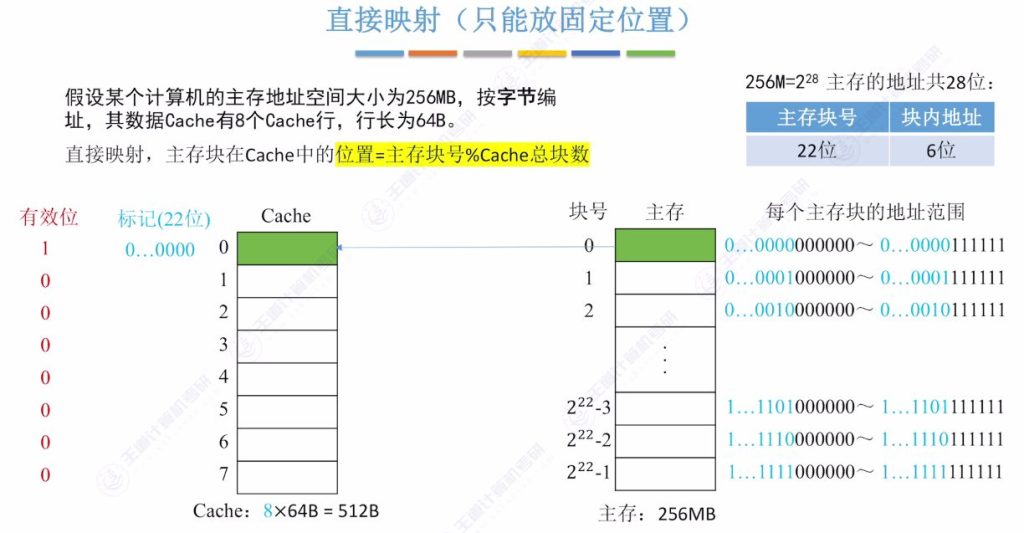
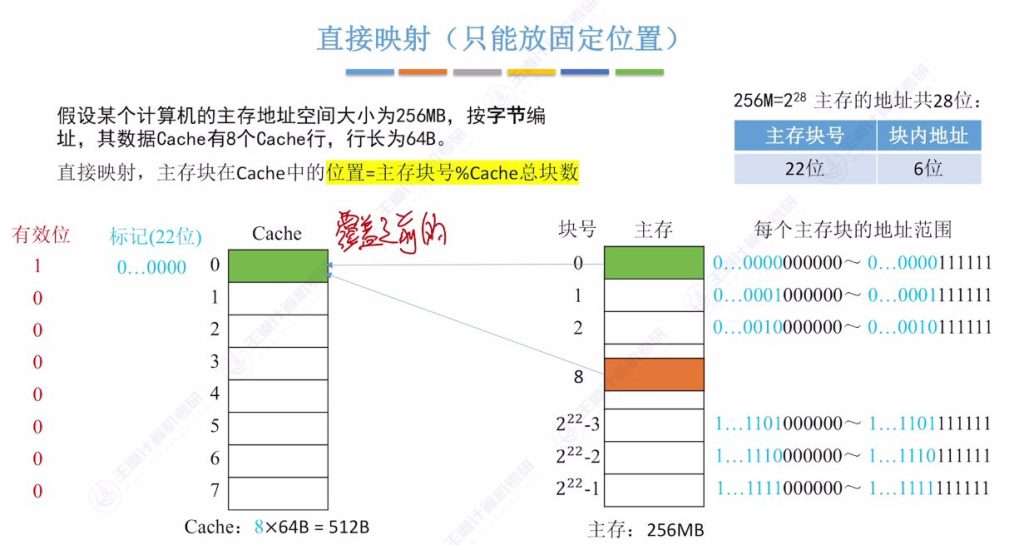
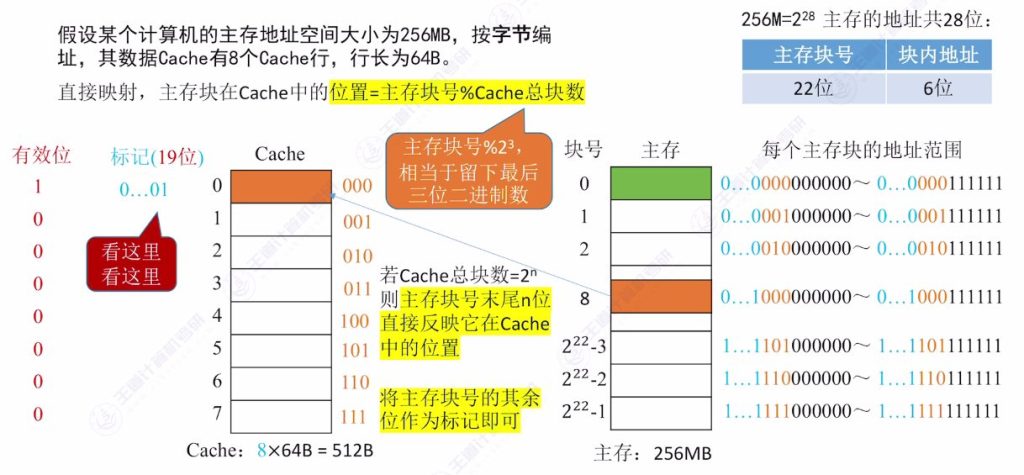
直接映射的定义
- 固定位置特性: 每个主存块只能放到Cache的固定位置,位置确定方式为主存块号对Cache总块数取余。例如主存块号0对8取余为0,只能放在Cache第0行。
- 标记位优化: 当Cache总块数为 2n 时,主存块号末尾n位可直接反映Cache位置,因此标记位只需存储主存块号前几位。例如8行Cache(23)只需存储前19位标记,舍弃末尾3位。
- 地址结构: 主存地址28位分为:标记(19位) + 行号(3位) + 块内地址(6位)。其中行号对应主存块号末3位。
- 空间利用率问题: 即使其他Cache行空闲,主存块仍只能放在固定位置,导致空间利用率低于全相联映射。
2.4 直接映射 – 优化标记
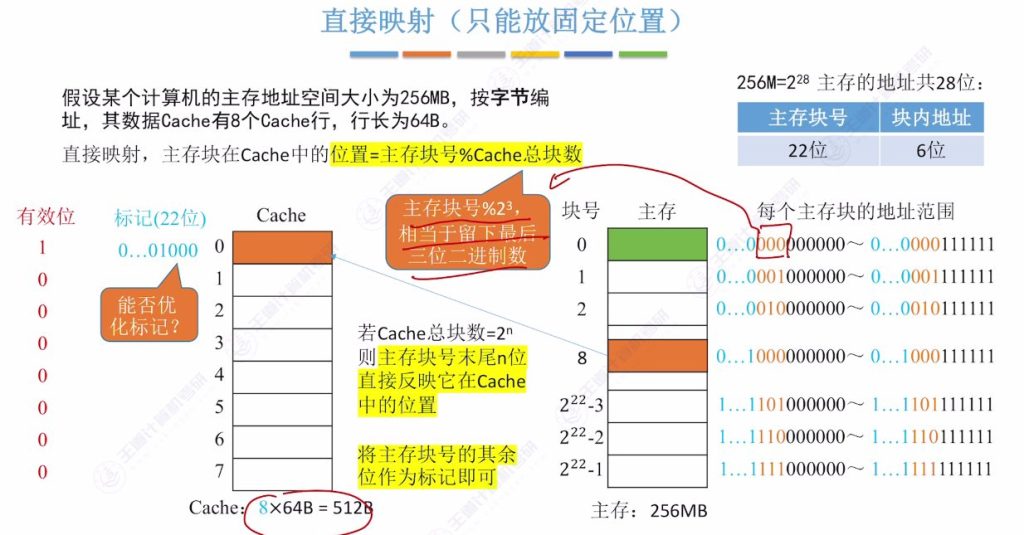
2.5 “直接映射”如何访存
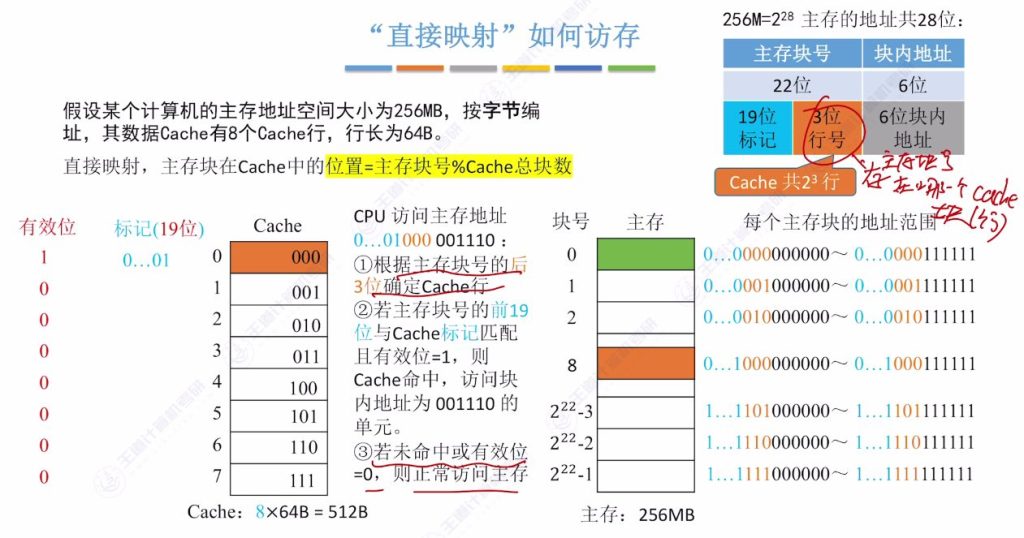
- 定位步骤:
- 提取主存地址末3位确定Cache行号
- 对比该行标记位与主存块号前19位
- 检查有效位是否为1
- 命中判断: 当标记匹配且有效位为1时命中,根据块内地址(6位)读取数据
- 缺失处理: 若标记不匹配或有效位为0,需访问主存获取数据
- 性能特点: 只需比较一个标记位,查找速度最快但容易产生冲突替换
2.6 组相联映射
组相联映射的定义
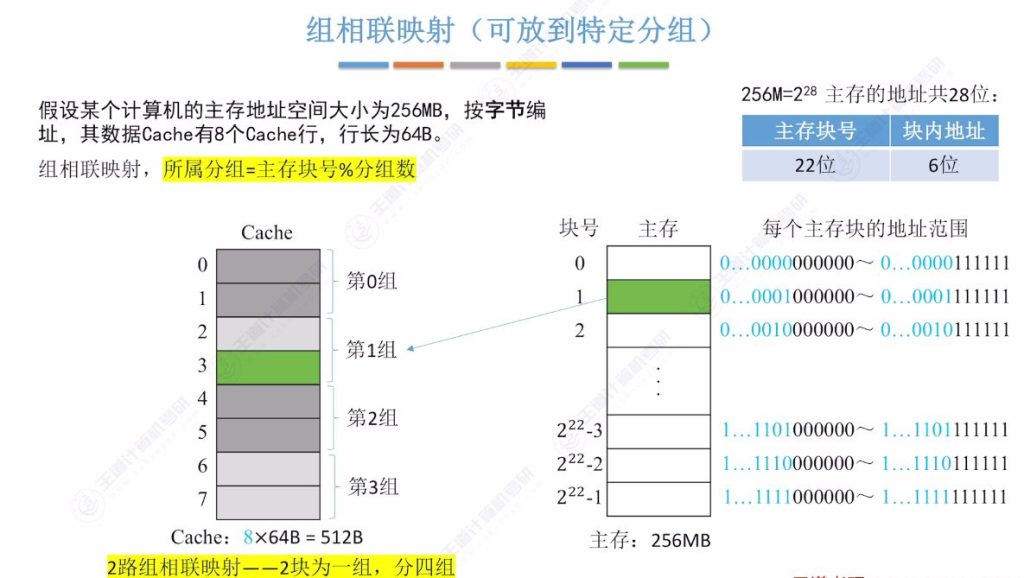
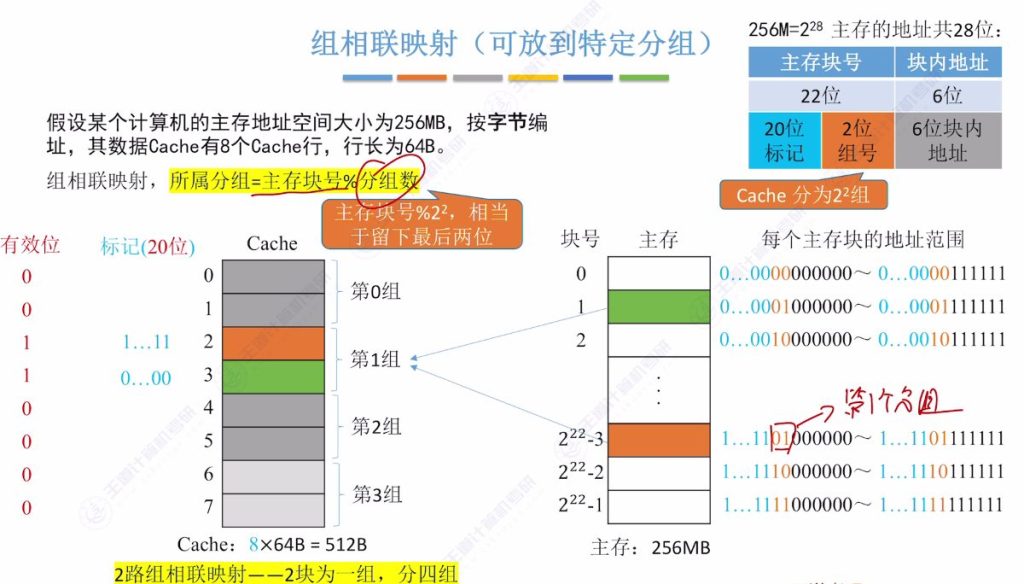
- 分组特性: 主存块可放入特定组内任意位置,组号=主存块号%总组数。例如2路组相联8行Cache分为4组(22)
- 标记位优化: 组数为2n时,主存块号末n位反映组号,标记只需存储前(22-n)位。例如4组Cache只需存储前20位标记
- 地址结构: 主存地址分为:标记(20位) + 组号(2位) + 块内地址(6位)
- n路组相联: 每n个Cache行为一组,如2路组相联即每组2个Cache行
2.7 “组相联映射”如何访问
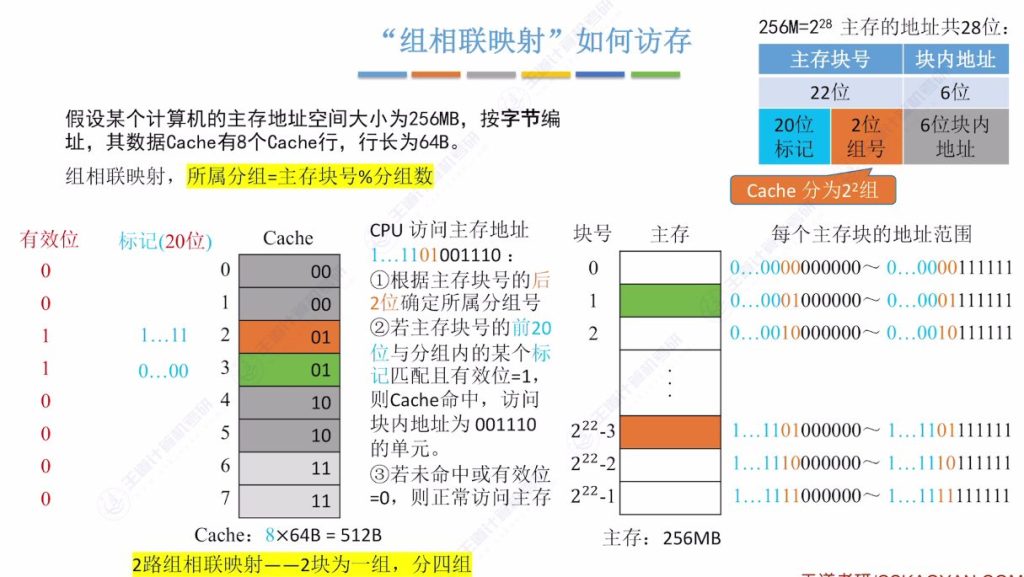
- 定位步骤:
- 提取主存地址末2位确定组号
- 在该组内逐个对比标记位(20位)
- 检查有效位状态
- 命中判断: 组内任一行的标记匹配且有效位为1即命中
- 替换策略: 组内空闲时可任意放置,无空闲时需采用替换算法
- 性能平衡: 兼具全相联的灵活性和直接映射的查找效率,实际应用最广泛
2.8 知识回顾

- 全相联映射:
- 优点: 空间利用率最高(100%),命中率最高
- 缺点: 需要比较所有行的标记,查找速度最慢
- 地址结构: 标记(22位全块号) + 块内地址(6位)
- 直接映射:
- 优点: 只需比较1个标记,查找速度最快
- 缺点: 空间利用率最低,容易产生冲突
- 地址结构: 标记(19位) + 行号(3位) + 块内地址(6位)
- 组相联映射:
- 折中特性: 组内全相联+组间直接映射,综合效果最优
- 地址结构: 标记(20位) + 组号(2位) + 块内地址(6位)
- 关键参数: n路组相联决定每组包含的Cache行数
- 硬件实现提示:
- 当Cache行数为 2n 时,取余运算可简化为截取二进制末n位
- 标记位存储时可省略反映位置信息的末n位以节省空间
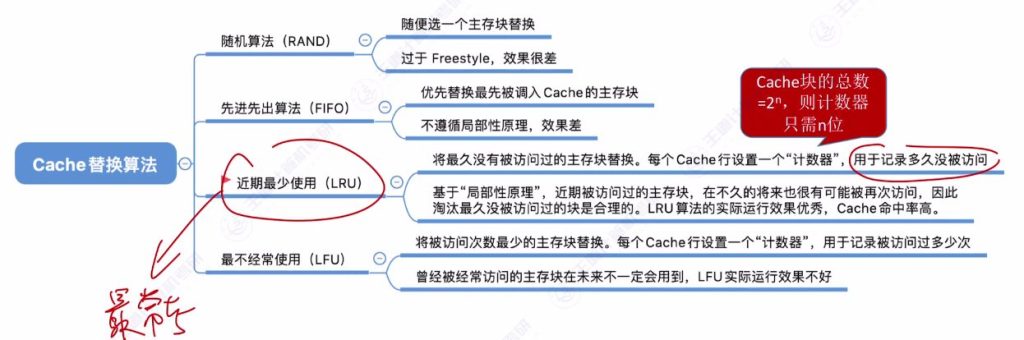
三、Cache替换算法
- 四种算法:
- 随机算法(RAND)
- 先进先出算法(FIFO)
- 近期最少使用算法(LRU)
- 最近不经常使用算法(LFU)
3.1 有待解决的问题
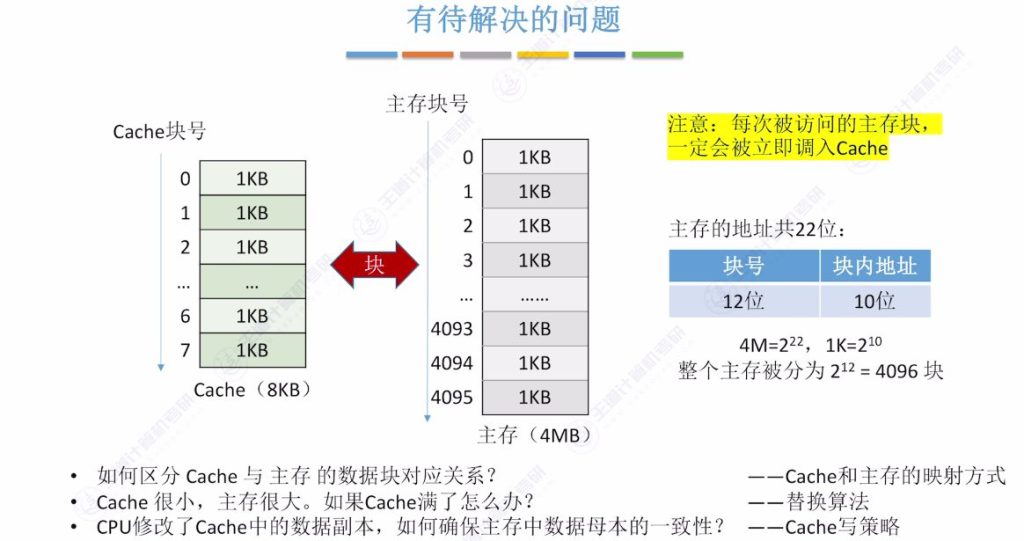
- 映射关系问题: 如何区分Cache与主存的数据块对应关系?——通过Cache和主存的映射方式解决
- 数据一致性问题: CPU修改Cache中的数据副本后,如何确保主存中数据母本的一致性?——通过Cache写策略解决
- 容量问题: Cache容量远小于主存,当Cache装满后如何处理?——通过替换算法解决
3.2 替换算法解决的问题
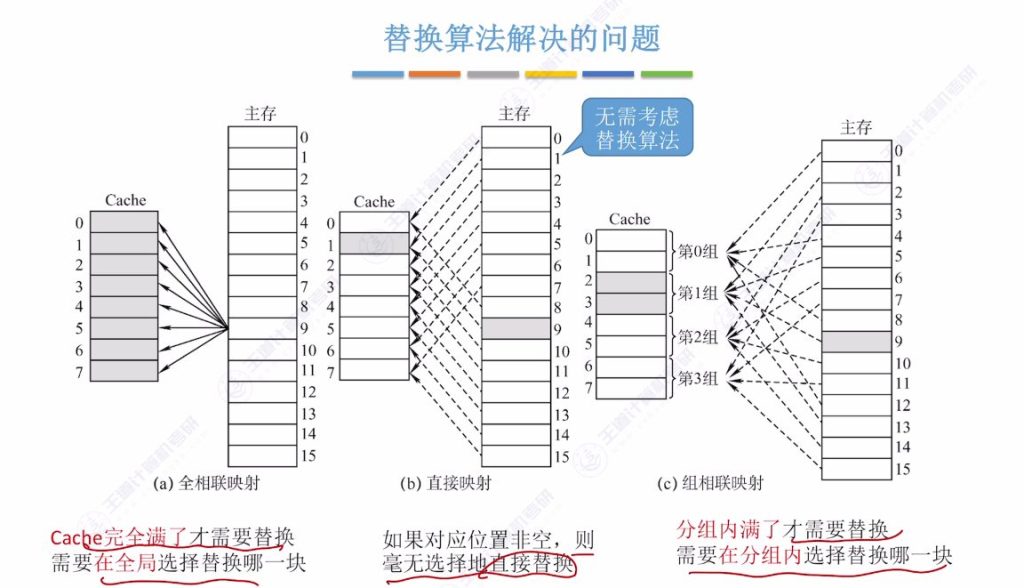
- 全相联映射:
- 特点: 每个主存块可放入Cache任意位置
- 替换时机: 仅当整个Cache装满后才需要替换
- 直接映射:
- 特点: 每个主存块只能放入Cache指定位置
- 替换特点: 无需选择,直接替换指定位置原有数据
- 组相联映射:
- 特点: 每个主存块放入指定组内的任意位置
- 替换时机: 仅当所属Cache组装满后才需要替换
- 算法适用范围: 仅全相联映射和组相联映射需要替换算法,直接映射无需考虑
3.3 随机算法(RAND)
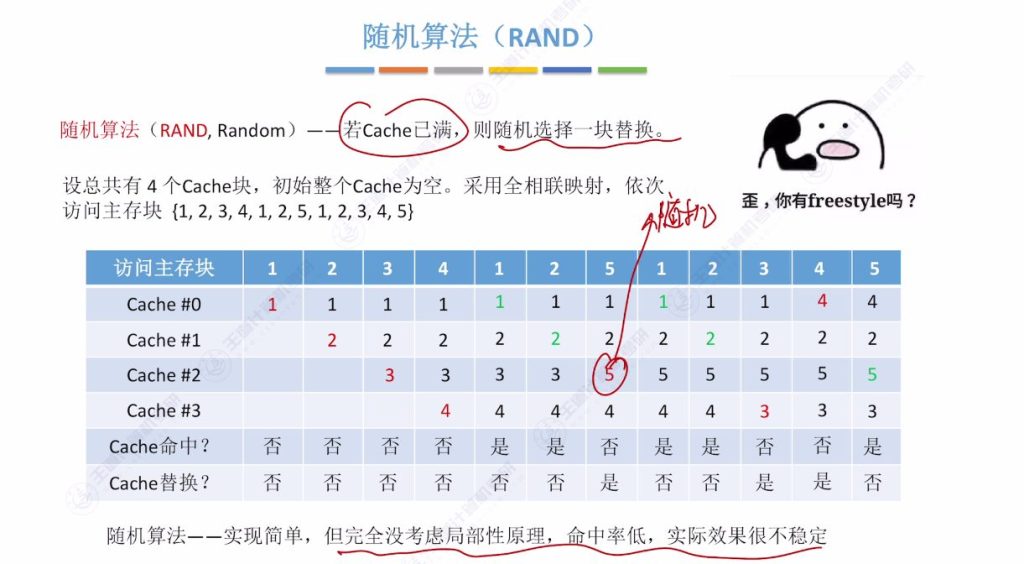
- 算法原理: Cache满时随机选择一块替换
- 示例系统:
- 4个Cache块,初始为空
- 全相联映射
- 访问序列:{1,2,3,4,1,2,5,1,2,3,4,5}
- 执行过程:
- 前4次访问(1,2,3,4):依次装入Cache块0-3,无替换
- 第5-6次访问(1,2):命中
- 第7次访问(5):随机替换3号块(示例选择)
- 后续替换均随机选择
- 特点:
- 实现简单但效果不稳定
- 未考虑程序局部性原理
- 命中率可能很低
3.4 先进先出算法(FIFO)
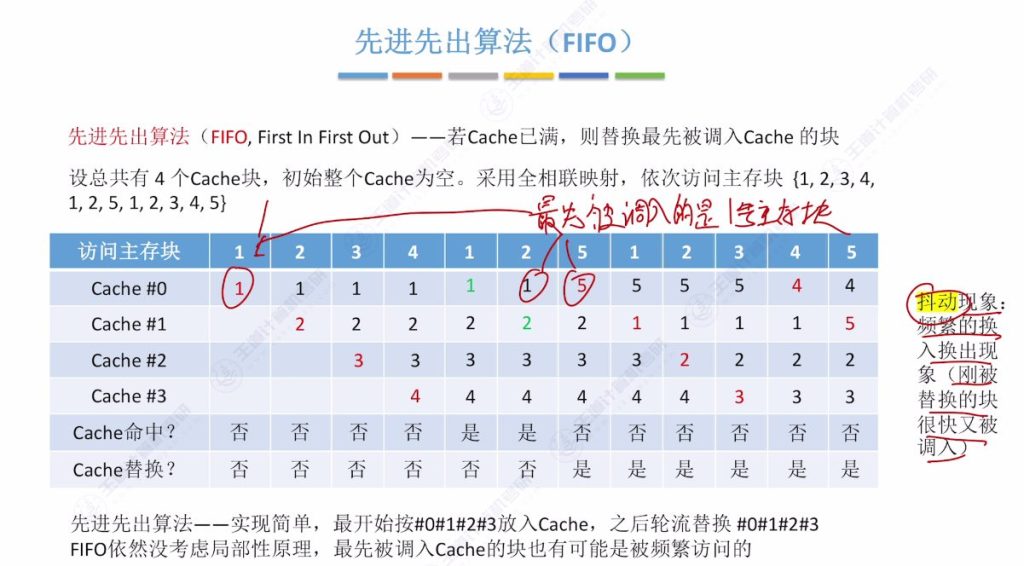
- 算法原理: Cache满时替换最先被调入的块
- 相同示例系统:
- 4个Cache块,初始为空
- 全相联映射
- 访问序列:{1,2,3,4,1,2,5,1,2,3,4,5}
- 执行过程:
- 前4次访问(1,2,3,4):依次装入Cache块0-3
- 第5-6次访问(1,2):命中
- 第7次访问(5):替换最先装入的1号块
- 第8次访问(1):替换当前最先的2号块
- 后续按装入顺序依次替换
- 硬件实现:
- 初始按行号顺序装入
- 替换时循环替换0→1→2→3→0…
- 特点:
- 实现简单但命中率低
- 未考虑局部性原理(如常用函数可能最先被调入)
- 可能出现抖动现象(刚被替换的块立即又被访问)
- 实际运行效果不理想
3.5 近期最少使用算法(LRU)



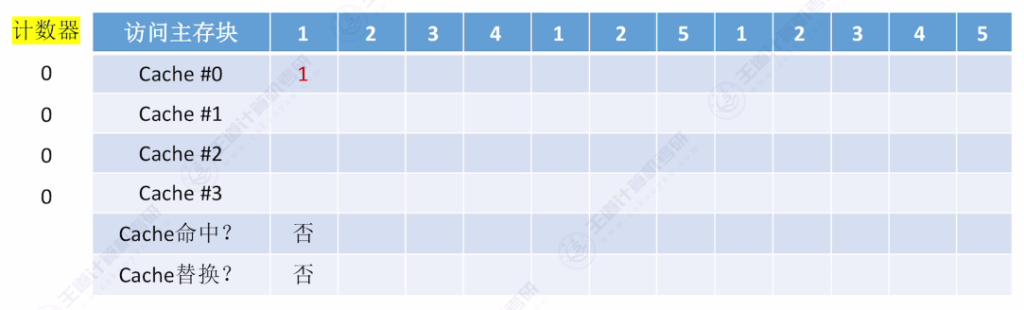
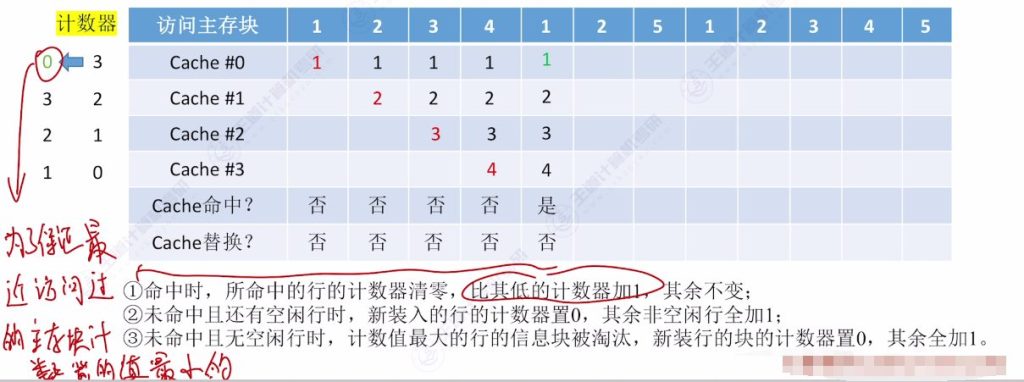
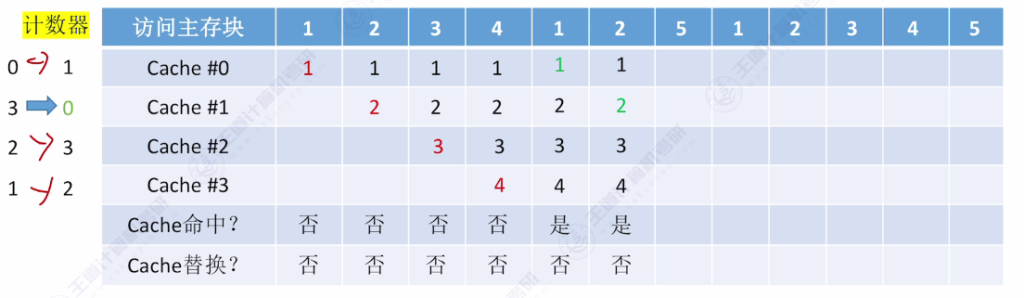
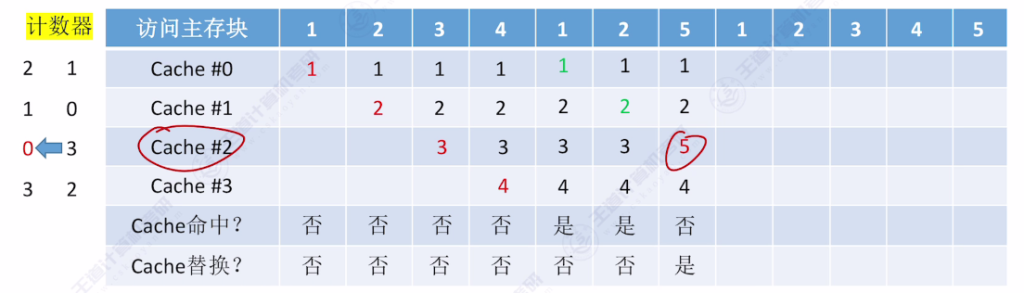
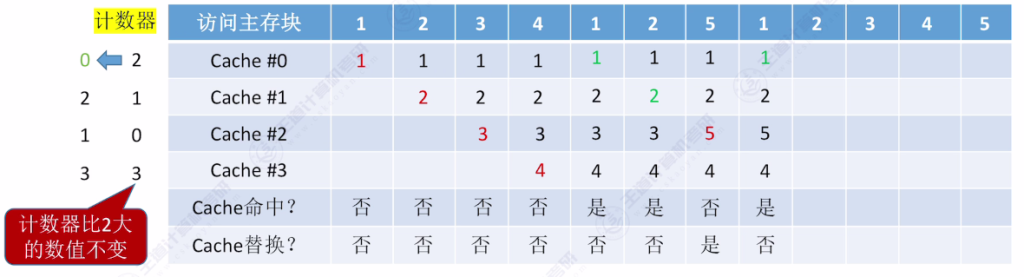
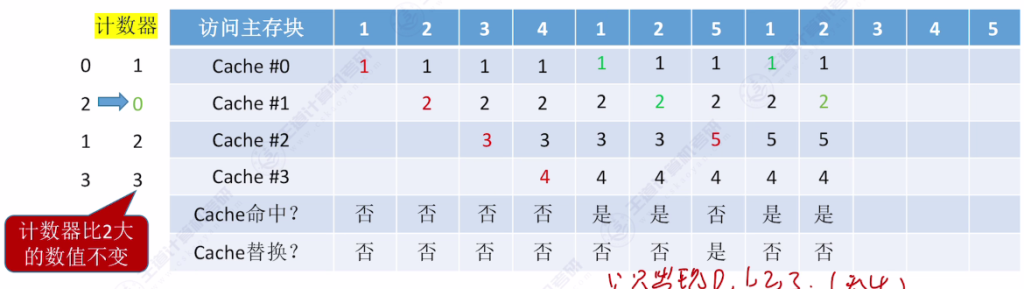
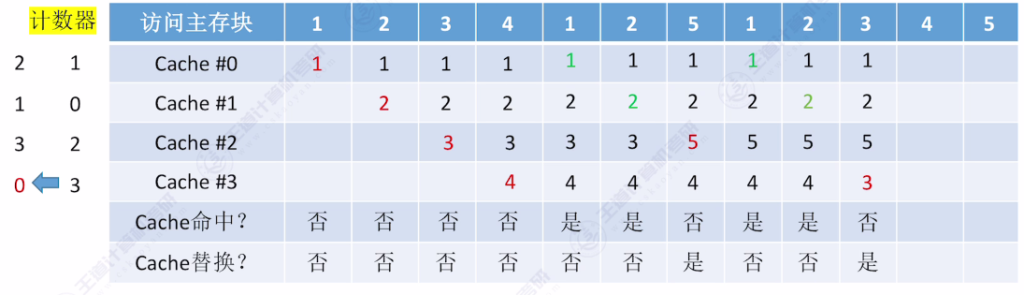
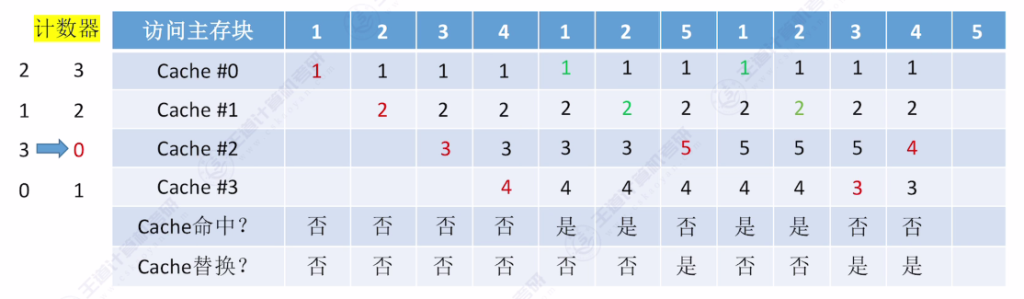
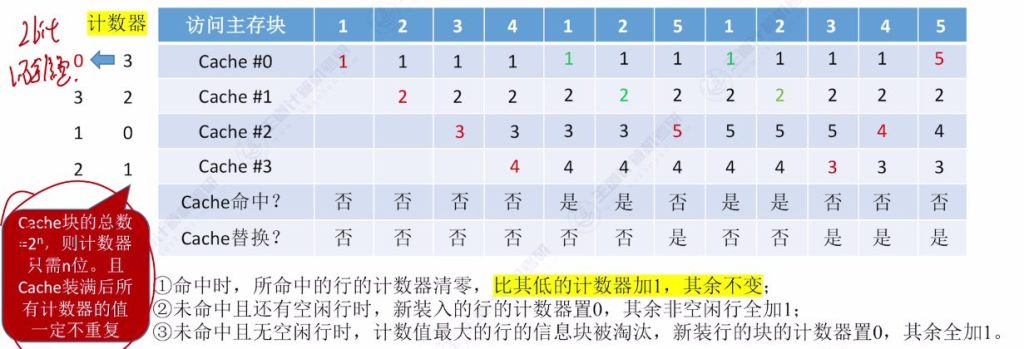
- 核心思想:为每个Cache块设置计数器,记录未被访问的时间长度,替换时选择计数器最大的块
- 硬件实现:
- 每个Cache行需增加计数器字段
- 初始时所有计数器置零
- 命中时:被访问行的计数器清零,比其小的计数器加一
- 未命中时:空闲行计数器置零,非空闲行计数器加一
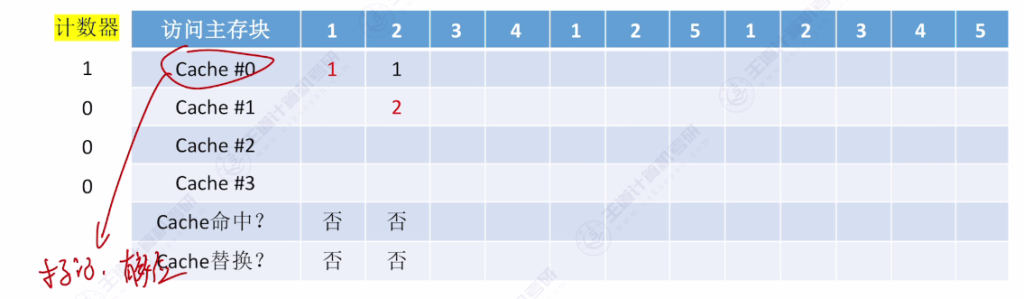
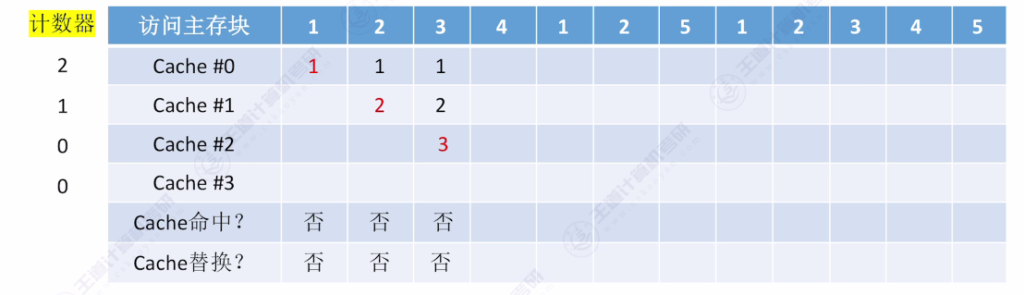
- 手算技巧:从当前访问位置往前查找,最后一个出现的主存块即为替换对象
- 访问示例:
- 初始状态:4个空Cache块
- 访问序列:{1,2,3,4,1,2,5,1,2,3,4,5}
- 关键替换点:访问5时替换3(计数器最大值为3)
- 硬件优化:
- 当Cache块数为 2n 时,仅需n位计数器
- 保证计数器值始终在0到 2n−1 范围内
- 算法优势:
- 遵循时间局部性原理
- 实际运行效果优秀,命中率高
- 局限性:
- 当频繁访问块数超过Cache容量时仍会发生抖动
- 示例:循环访问{1,2,3,4,5}序列时
LRU 手算过程
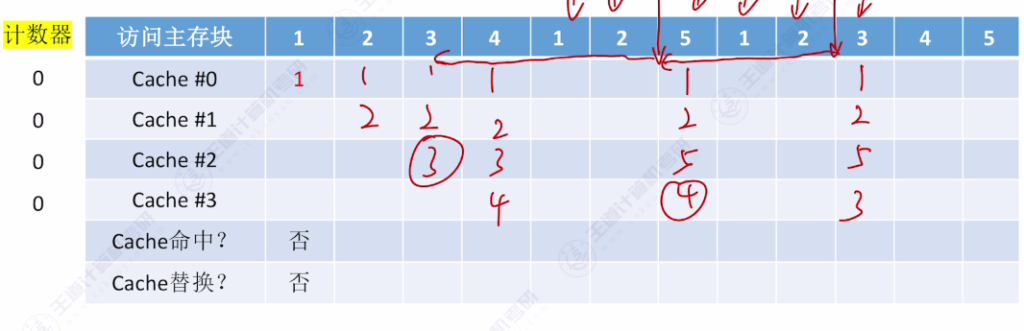
LRU 计算过程
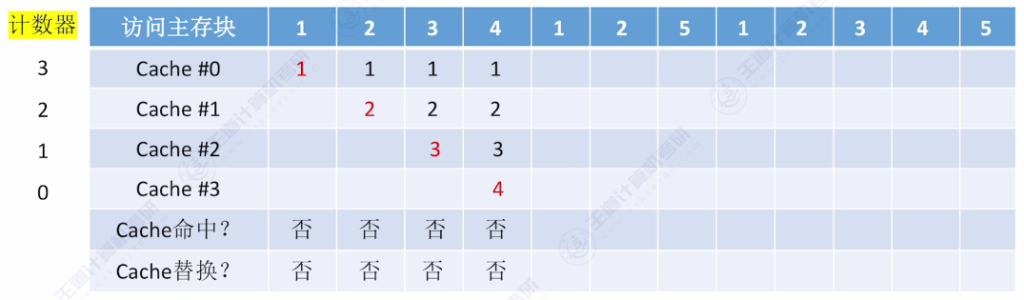
- 为了保证最近访问过的主存块计数器的值最小
- 计数器最大值是0 – 3
3.6 最不经常使用算法(LFU)
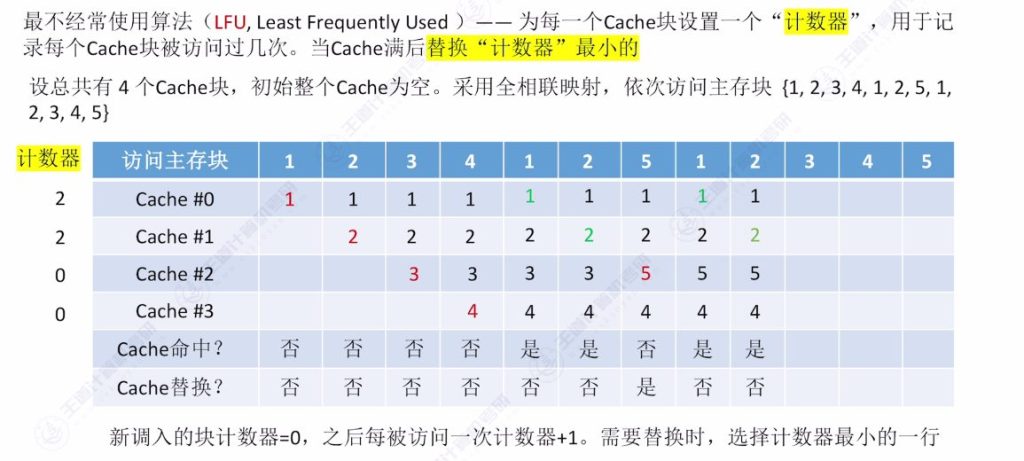
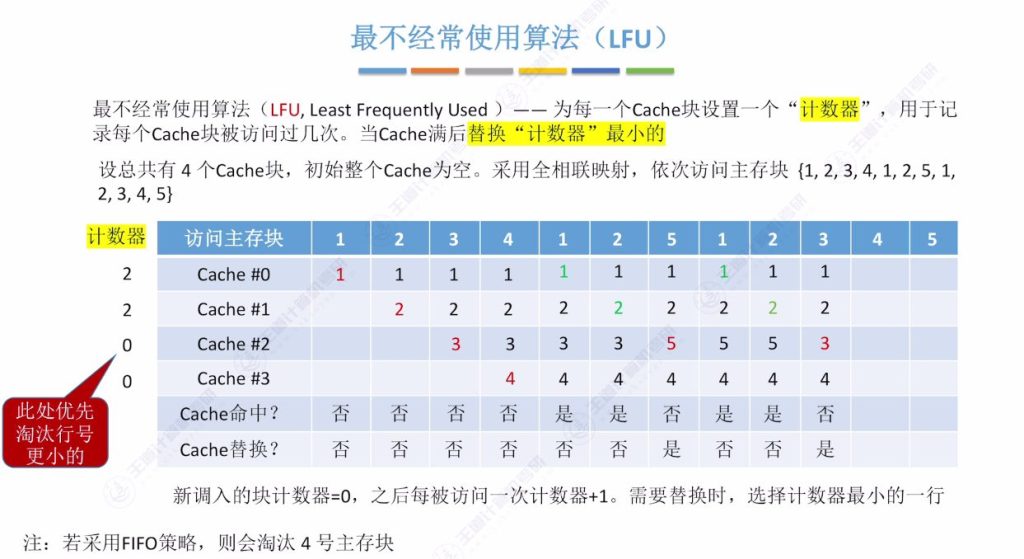
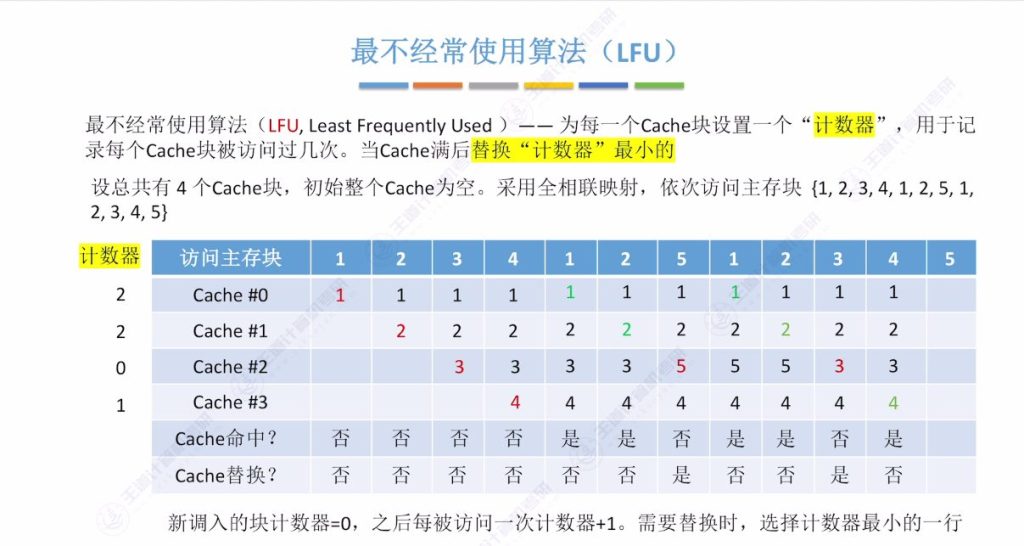
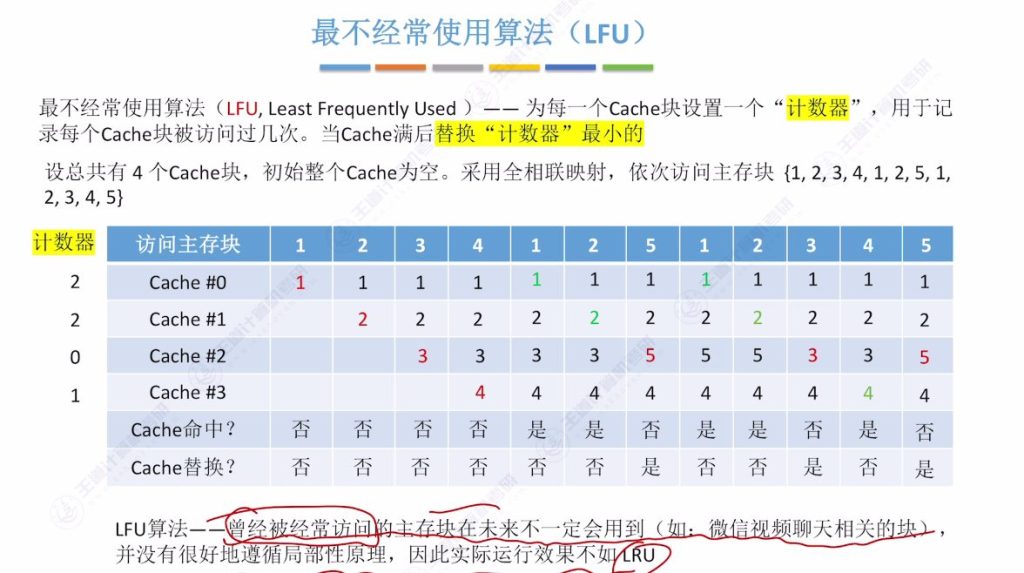
- 核心思想:记录每个Cache块被访问次数,替换时选择计数器最小的块
- 实现细节:
- 计数器记录累计访问次数
- 新调入块计数器初始为0
- 每次命中后对应计数器加1
- 访问示例:
- 相同访问序列:{1,2,3,4,1,2,5,1,2,3,4,5}
- 关键替换点:
- 首次访问5时需在计数器同为0的块中选择(按行号优先替换)
- 后续替换遵循最小计数原则
- 计数器特点:
- 可能增长到很大数值
- 需要较多二进制位表示
- 算法缺陷:
- 不符合时间局部性原理
- 历史高频访问块可能长期驻留
- 实际命中率不高
- 示例:视频聊天相关数据块计数器持续增长但后续不再使用
3.7 知识回顾
- 随机算法(RAND):
- 实现简单但效果差
- 完全随机选择替换块
- 先进先出(FIFO):
- 替换最先调入的块
- 不遵循局部性原理
- 可能产生Belady异常(Cache增加但命中率下降)
- 近期最少使用(LRU):
- 实际效果最优
- 严格遵循局部性原理
- 硬件实现需要n位计数器(2n个Cache块时)
- 最不经常使用(LFU):
- 理论上统计全局访问频率
- 实际运行效果不佳
- 计数器需要较多存储空间
- 重点考点:
- LRU的手算方法和硬件实现
- 各种算法的核心思想对比
- 局部性原理的理解应用
四、Cache写策略
- 核心问题: 当CPU修改Cache中的数据副本后,如何保持主存和Cache的数据一致性
- 问题背景: Cache中保存的只是主存数据的副本,写操作会导致副本与母本不一致
- 研究范围: 仅探讨写操作情况(读操作不会导致数据不一致问题)
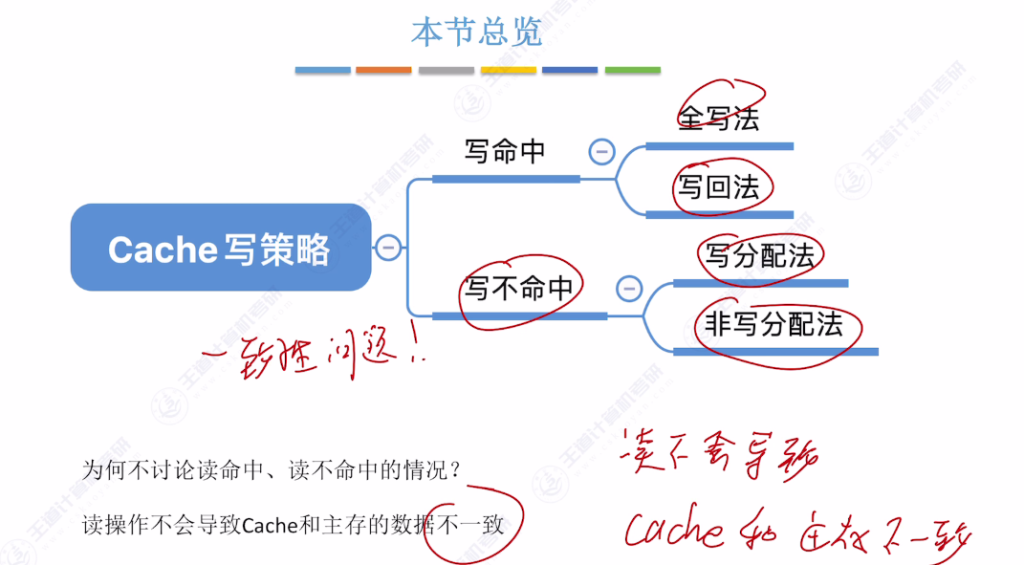
- 写命中情况:
- 全写法(写直通法,write-through)
- 写回法(write-back)
- 写不命中情况:
- 写分配法(write-allocate)
- 非写分配法(not-write-allocate)
- 现代计算机应用:
- 多级Cache结构采用不同策略组合
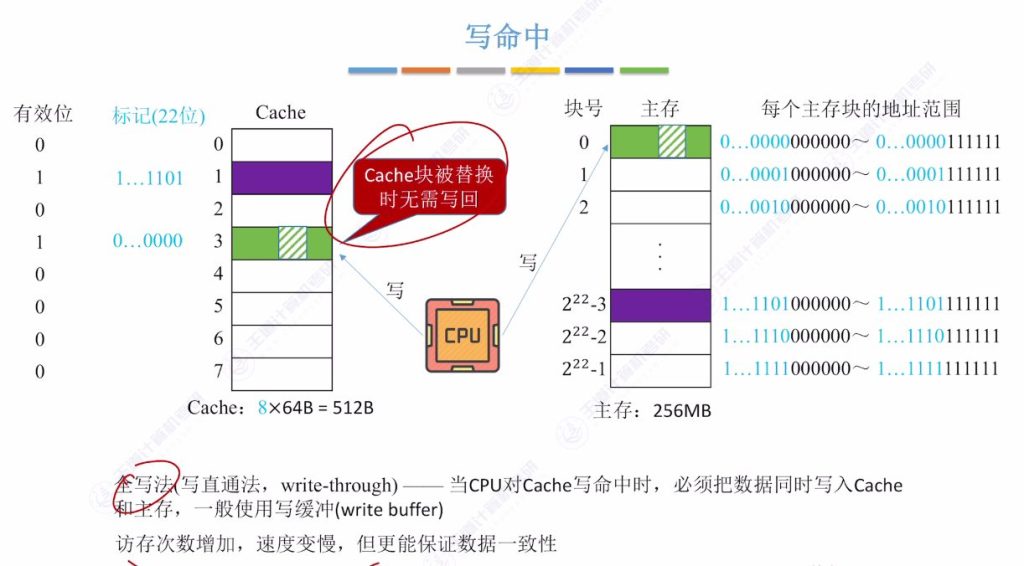
4.1 写命中 – 写回法
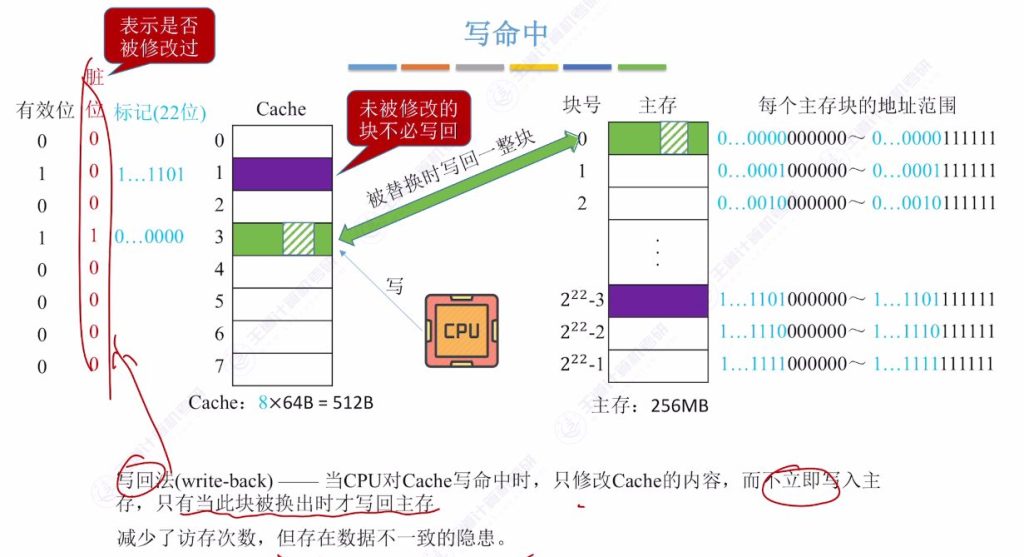
- 工作原理: 当CPU对Cache写命中时,只修改Cache内容,不立即写入主存,直到该块被换出时才写回
- 脏位机制:
- 每个Cache行增加1位脏位(dirty bit)
- 修改后置1,未修改保持0
- 替换时根据脏位决定是否写回
- 性能特点:
- 优点:减少访存次数,提升写操作速度
- 缺点:存在数据不一致隐患
- 适用场景: 适合写操作频繁的系统
4.2 写命中 – 全写法
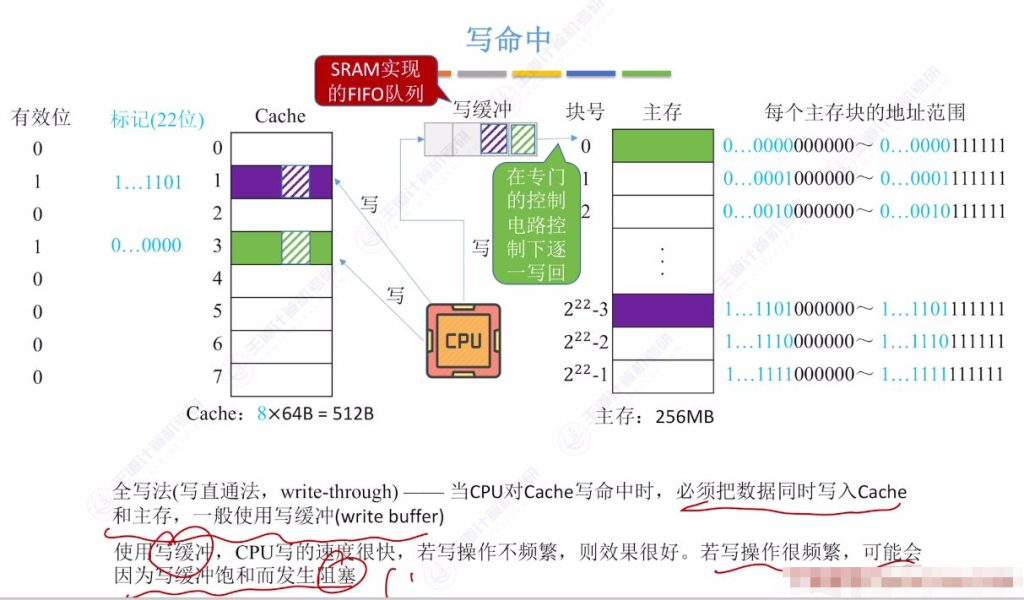
- 工作原理: 当CPU对Cache写命中时,必须同时写入Cache和主存
- 写缓冲优化:
- 使用SRAM实现的先进先出队列
- CPU先将数据写入Cache和写缓冲
- 专用电路异步将数据从缓冲写入主存
- 性能特点:
- 优点:保证数据一致性
- 缺点:增加访存次数,写操作速度较慢
- 缓冲饱和时会导致CPU阻塞
- 适用场景: 适合写操作不频繁的系统
4.3 写不命中 – 写分配法
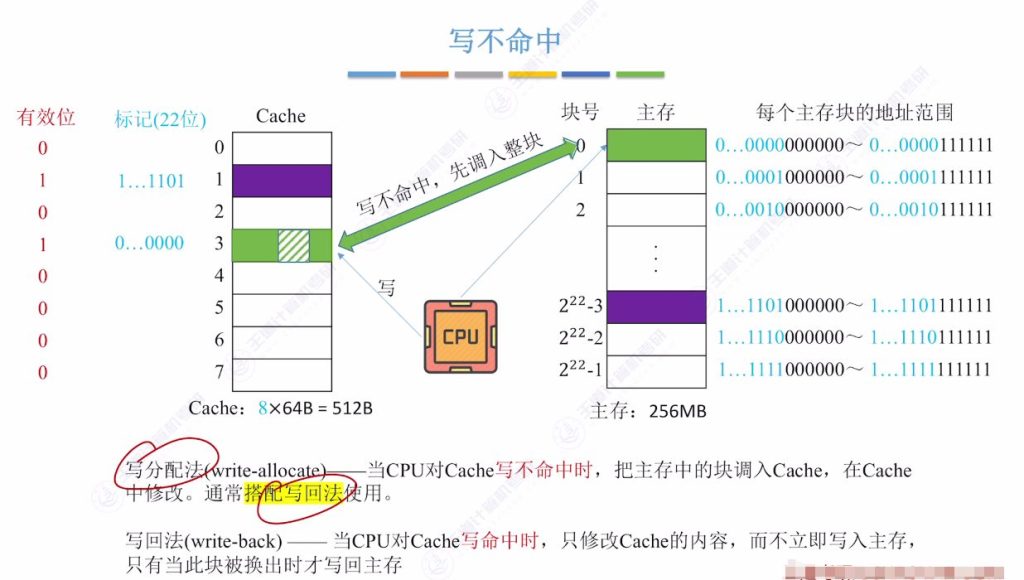
- 工作原理: 当CPU写不命中时,先将主存块调入Cache,然后在Cache中修改
- 搭配策略: 通常与写回法配合使用
- 特点:
- 适合后续可能频繁访问同一数据块的情况
- 减少后续访问的缺失率
4.4 写不命中 – 非写分配法
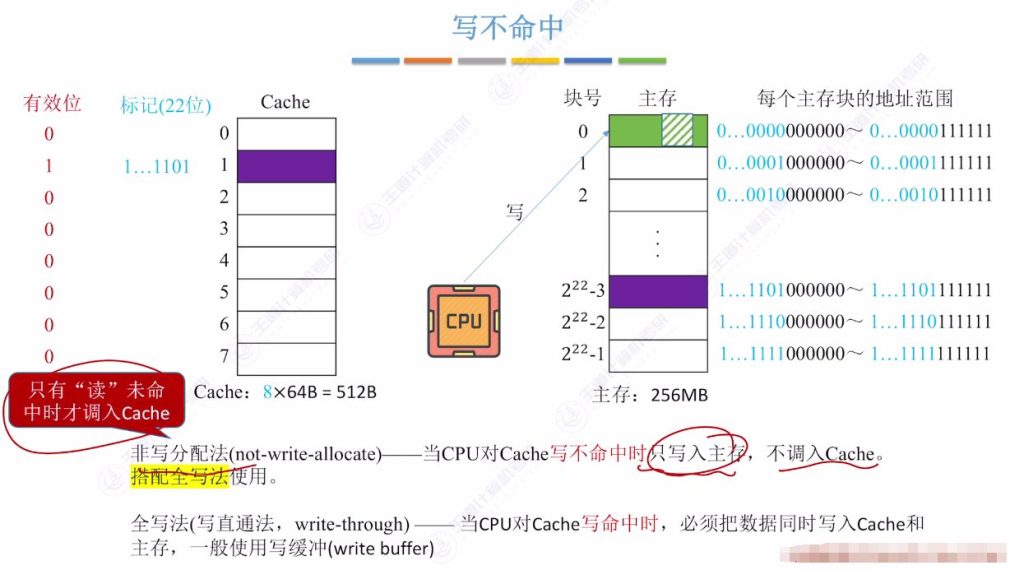
- 工作原理: 当CPU写不命中时,直接写入主存,不调入Cache
- 搭配策略: 通常与全写法配合使用
- 特点:
- 只有读操作未命中时才会调入Cache
- 减少不必要的Cache占用
4.5 多级Cache策略
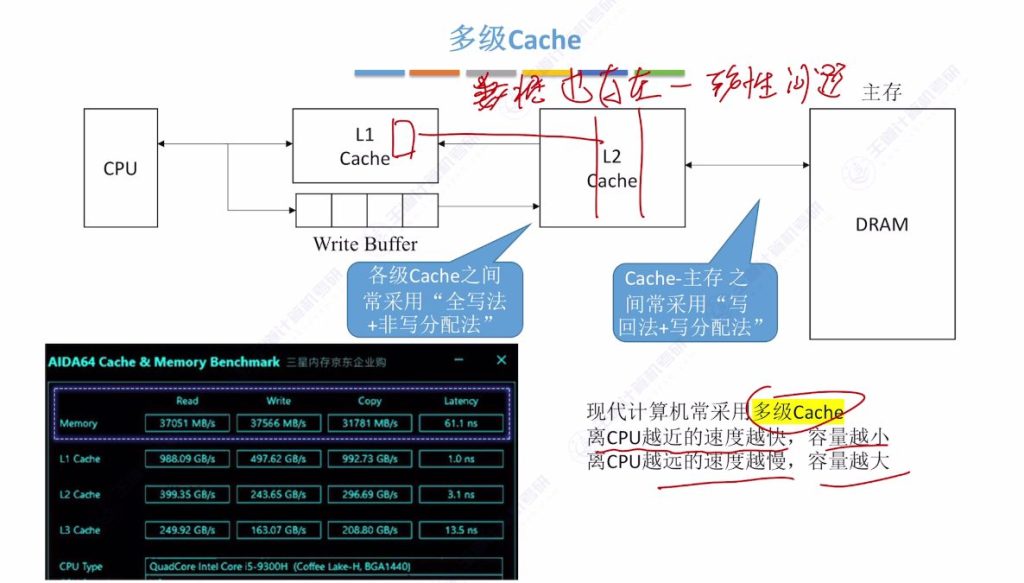
- 层级特点:
- L1 Cache:最接近CPU,速度最快(约1000GB/s),容量最小
- L2 Cache:速度约为L1的一半
- L3 Cache:速度更慢,容量更大
- 主存(DRAM):速度最慢,容量最大
- 策略组合:
- 各级Cache间:全写法+非写分配法
- Cache与主存间:写回法+写分配法
- 性能考量:
- 平衡速度与一致性要求
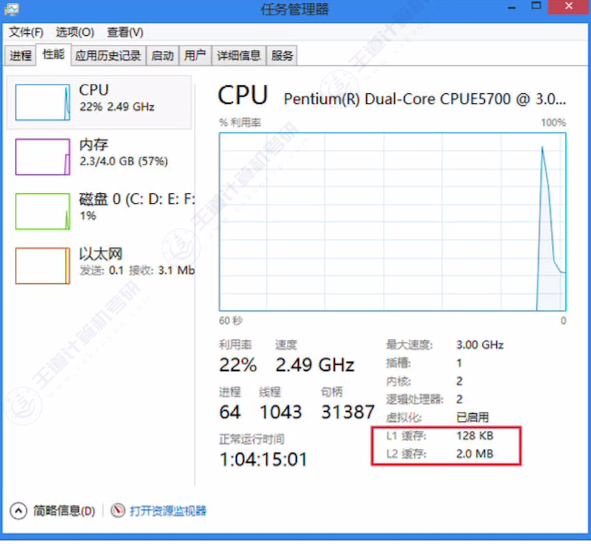
- 通过任务管理器可查看各级Cache信息
4.6 知识回顾
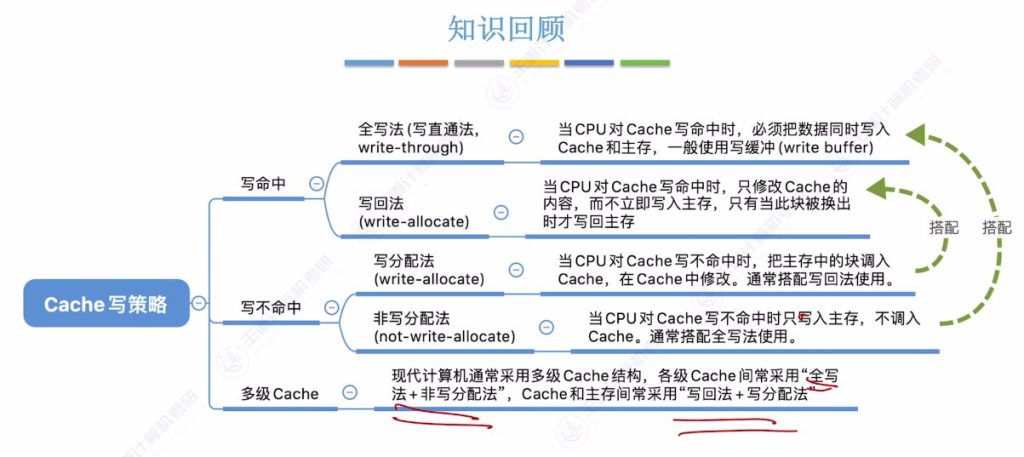
- 写命中策略:
- 全写法:保证一致性但速度慢
- 写回法:速度快但存在不一致风险
- 写不命中策略:
- 写分配法:搭配写回法使用
- 非写分配法:搭配全写法使用
- 设计原则:
- 在保证数据一致性的前提下尽可能提升速度
- 多级Cache采用分层策略组合
- 实现目标:
- 解决Cache与主存数据一致性问题
- 平衡系统性能与成本
本网站原创文章版权归何大锤的狂飙日记所有。发布者:何大锤,转转请注明出处:何大锤的博客

